Глава 3. ЧЕЛОВЕЧЕСКИЙ ЯЗЫК
Информация о цивилизациях человечества, как оказалось, самым тесным образом сопряжена с языком. В частности, названия букв алфавита соотносятся с номерами регионов Древнего Мира. Вторая буква многих алфавитов под названием Бета (Бет), отражая идею укрытия, и имея числовое значение 2, является в то же время номером второго региона, Египта, региона, занимавшегося химией. Точно так же и буква Гамма, Гим, Гимель с числовым значением три, соотносясь по звучанию с Гималаями, отражает идею тельца, телесности, а, значит, и физики (напомню, что телесный значит физический), является в то же время и номером Индии. Буква Далет, Даль, Дельта (числовое значение – 4) является номером Аравии Арабская буква Вав (و ), являясь откровенной перевернутой шестеркой, соотносится с Китаем, и именно удвоенную шестерку или, что то же самое, 69 мы видим в символе инь-ян.
Из этого сам собой напрашивается вывод о том, что перед нами единая система, завязанная на культы, языки, цифры, этносы, из чего вытекает, что для того, чтобы разобраться, скажем, с религиями и народами, следует разобраться с языком Подробности читатель найдет в других моих работах. Здесь же кратко изложу основные положения моей теории глоттогенеза.
Уже из предшествующего материала невооруженным глазом видно, что разные способы письма являют собой систему. Она не может быть выведена из царапок на глине или зарубок на камне или дереве, как пытаются это сделать некоторые специалисты. На самом деле первоначальная письменность построена на логико-символических основаниях, но настолько простых, что понять ее не составляет труда даже для первоклассника.
Пресвятая Троица
В начале всей языковой конструкции лежит графическая точка. Арабы изобразили бы его в виде квадрата, но для нас её форма не важна. Далее, применяя принцип перемещения или сканирования, из точки получаем линию. След движения точки есть линия. Далее из линии «угловым сканированием линии» угол. Как если бы мы раздвинули ножки циркуля.
![]()
Эти графические построения символичны. Точка символизирует абсолютное начало, в христианской терминологии – Бога-отца, поскольку точка, перемещаясь прямолинейно, порождает линию. Следовательно, порожденная линия символизирует Бога-Сына, иначе саму всевозрождающуюся жизнь, поскольку любая линия кончается точкой (т.е. превращается в отца), которой может эта линия быть продолжена. Что касается угла, то это символ Святаго Духа, иначе человеческого интеллекта (не замороченного, светлого, пробудившегося) или самого человека, как его носителя, ибо только он в состоянии отклонить линию жизни от своей естественной устремленности.
Угол в единстве всех трех элементов в христианской мистике известен под названием Пресвятой Троицы, а до нее в пифагорейской школе речь шла о Священной Триаде, под которой Пифагор (ошибочно) понимал три первые цифры. Три первые цифры не составляют замкнутой системы и потому не могут претендовать на то, чтобы называться Священной Триадой. Ограничение натурального ряда чисел тремя – явная натяжка со стороны Пифагора.
Что касается Пресвятой Троицы, то она намного ближе к истине. По крайней мере неплохо схвачена функция элементов. К сожалению, для христиан Пресвятая Троица являет собой таинство великое, до которой, как считают христианские богословы, не может возвысится разум человеческий (добавим: спящий). Для проснувшегося разума таинств нет, и в этом можно убедиться из последующего изложения.
Нетрудно сообразить, что угол есть лишь момент развертывания точки в сферу. Поэтому точка, угол и сфера – разные моменты единого явления, единой сущности, которая есть пульсирующая сфера. Все, что на свете ни наесть круглого – все Пресвятая Троица. Все, что на свете ни наесть колеблющегося – все Пресвятая Троица. Пресвятая Троица – есть самая общая формула структурирования бытия.
То, что точка – абсолют, было известно еще в глубокой древности. Но ведь и угол и линия лишь разные ипостаси единого абсолюта. Любопытно, что в Вавилоне нуль как символ оборота обозначали кружком с точкой посередине, мы обозначаем его кружком, а арабы – точкой (преимущественно квадратной).
Но самое любопытное в том, что из угла или, что то же самое, единицы конструируются цифры.
![]()
Это делается простым сложением углов
(единиц). Нетрудно сосчитать и убедиться, что в каждой цифре столько
графических углов (единиц), сколько реально она их содержит в числовом
выражении. Эти угловатые цифры я называю протоцифрами. Те арабские цифры,
которыми мы пользуемся сейчас, отличаются скругленностью углов. Так писать
удобнее.
Попытки некоторых
"ученых" запатентовать "угловые цифры" в качестве открытия
смешны. О них знает каждый второй бедуин.
Как бы там ни было, можно сказать, что и арабские цифры сконструированы по лекалу Пресвятой Троицы.
Цифровой ряд тоже символичен. Цифры нумеруют месяцы беременности, исчисленные в солнечном календаре. Выше было сказано, что угол – есть символ разума, тогда цифры символизируют помесячное развитие эмбриона в утробе матери. Срок исчислен в солнечном календаре. Поэтому не случайно девятка рисует нам эмбрион, хотя из девяти углов можно было бы составить самые разные конфигурации. Значит, и беременность и эмбрион, и сам человек – всего лишь ипостаси Пресвятой Троицы.
Арабские буквы, как мы увидим ниже, происходят от арабских цифр и являют собой простые номера звуков. Это видно и невооруженным глазом. Например, первая буква Алиф имеет числовое значение – 1, пишется единицей ( ا ), шестая буква Вав имеет числовое значение – 6 и обозначается шестеркой – و (перевернутой), девятая буква Т#а имеет числовое значение 9 и обозначается девяткой – ط (перевернутой), и так практически без исключений (кроме десятой буквы Йа – и варианта Алифа – ى ). Это значит, что и каждая буква – есть все та же ипостась Пресвятой Троицы.
При всем при этом каждой арабской букве строго соответствует один согласный звук, и звуков ровно столько, сколько букв. Такого порядка нет ни в одном алфавите мира. У нас, например, некоторые буквы не имеют числовых значений, в числовом ряде есть нарушения, некоторые числовые значения могут выражаться более, чем одной буквой, одна буква может отражать разные звуки и т.д.
Человеческий язык в целом един. Этнические языки, с которыми мы имеем дело, лишь разные грани единого кристалла, внутри которого как бы находится ядро. Его отражение на боковых гранях являют нам структуры конкретных языков. Весь этот кристалл структурируется семью уровнями на логикосимволической основе. Рассмотрим их последовательно.
1 уровень. Сотворение Пресвятой Троицы или, что то же самое, угла. Этот уровень описан выше.
2 уровень. Сотворение цифр, как это изложено выше.
3 уровень. Сотворение цифровой матрицы.
Если мы каждую цифру увеличим на порядок дважды и выпишем круглые единицы, десятки и сотни, включая и тысячу, так как это сделано ниже, получим числа брахми.
1 2
3 4 5 6 7
8 9
10 20
30 40 50 60 70
80 90
100
200 300 400 500 600 700 800 900
1000
Почему эти числа называются так, никому не известно. На самом деле это матрица беременности. Судите сами. 28 чисел брахми отражают менструальный цикл (28 дней), помноженный на 10 (число акушерских месяцев беременности), что дает 280 дней (срок беременности). Можно догадаться и без йогов, что брахми – это чуть-чуть искаженное русское слово бремя, тем более, что арабский X в некоторых почерках пишется как русское е.
Если вместо приписывания нулей к цифрам поворачивать сами цифры, получим арабский алфавит, буквы которого имеют числовые значения, зафиксированные таблицей чисел брахми.
Между прочим, и в русском языке для образования чисел 10, 100, 1000, точнее их названий, применяется вращение, только этого никто не видит. Берите первые две согласные из слов десять, сто, тысяча. Получите такой ряд ДС – СТ – ТС. Для выравнивания рада оглушите первую Д (в русском языке оглушение и озвончение часто искажает корни). Что означает этот вращающийся корень? В арабском он означает девятку: تسعة тисъат. А почему же в русском им обозначается десятка? А потому, что первично он обозначал не число, а последний месяц беременности. В лунном календаре – это десятый месяц, в солнечном – девятый. Вот ведь какая штука получается. Арабы пользуются лунным календарем, а корни используют так, словно живут при солнечном. Мы же, наоборот, пользуемся солнечным календарем, а в глубине души у нас – лунный. Невольно вспоминается обмен десятой буквой между арабским алфавитом и кириллицей.
Кстати, синонимичность девяти и десяти в скрытом виде обыгрывается в русских сказках: в тридевятом царстве, в тридесятом государстве. Здесь девять значит то же, что десять. Мало того. Если внимательно присмотреться к этим словам, обнаружится, что они отличаются друг от друга только одной буквой. В середине девяти стоит В, в середине десяти стоит С. Кажется, что В ни при каких обстоятельствах не переходит в С. И в самом деле в звуковом отношении В совсем не похожа на С. Однако в арабском алфавите В обозначается шестеркой и означает шесть, тогда как С означает 60, а по начертанию С являет собой зеркальное отражение арабского Вава (русской запятой و ). Если обратить внимание на то, что и первая буква этих слов д является зеркальным отражением девятки, то становится ясным, что в русском слове девять замаскировано превращение шестерки в девятку. В арабском языке эта идея отражается во вращении корня тисъ تسع "девять" – ست ситт "шесть". Теперь вы поняли, откуда у китайцев символ инь-ян?
Итак, данная таблица (цифровая матрица), как было сказано выше, состоит из двадцати восьми чисел, называемых числами брахми, числами беременности, отражающими лунный месяц. Каждая клетка этой таблицы соотносится с одним из 28 дней лунного месяца, а если считать ее отдельную клеточку равной 10 дням, то всю ее можно считать разверткой срока беременности, равного 280 дням или десяти лунным месяцам, которые по длине равны девяти солнечным месяцам. С другой стороны, числа данной таблицы строго соответствуют числовым значениям букв арабского алфавита, число которых равно 28. При том, что каждая буква точно соответствует одной из 28 согласных звуков арабского языка.
Арабские буквы
Числа брахми складываются из трех порядков – единиц, десятков и сотен. Каждый последующий порядок получен добавлением к исходной цифры нуля. Если же, как было сказано, вместо приписывания нуля (символа вращения или символа угла) вращать саму цифру, получим начертания арабских букв. Ниже помещены первые девять арабских букв (справа налево): А, Б, Г, Д, X, В, 3, X, Т в сравнении с арабскими цифрами. Во всех буквах до сих пор легко узнаются арабские цифры, пожалуй, кроме пятерки. Впрочем, арабы пишут пятерку именно так, кружком.
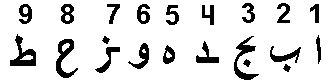
Поскольку арабские буквы получены вращением цифр, то и они воплощают в себе "Святой Дух", иначе, как мы сказали, – разум.
Если цифрой считать число, выраженное одним знаком, то в матрице мы имеем пока 28 цифр, которые станут буквами после размещения 28 арабских согласных звуков по клеткам матрицы. Отсюда вытекает, что арабские буквы – есть простые номера звуков.
Необходимость соединять эти цифры-буквы друг с
другом при письме затемнит их связь с исконными арабскими цифрами и люди, даже
сами арабы, долго еще не будут узнавать в арабских буквах знакомые всему миру
цифры. Попробуйте сами найти среди кувыркающихся цифр-букв арабской вязи
знакомые вам цифры в короткой фразе "я пишу строчки": أسطرا ا أكتب 'актуб 'астура(н). Вы должны увидеть справа
налево следующие цифры: 1, 2 (20), 4 (400), 2; 1, 3 (60), 9, 2(200), 1. Тройка
вместо шестидесяти появляется из-за того, что буква Син фактически замещена в
арабском алфавите буквой Шин (числовое значение – 300). Это еврейское влияние.
Евреи буквы С и Ш пишут одинаково, как русское Ш.
Если эту фразу написать почерком рукъа, узнать цифры вам будет гораздо легче.

Порядок нумерации звуков
Вопрос о том, в каком порядке размещены звуки в цифровой матрице, должен быть предварен другим: как получены 28 звуков? Обратите внимание на их количество. Филологи всерьез считают, что звуки речи возникли из диких воплей обезьян. Вряд ли из диких воплей обезьян можно получить именно 28 согласных, ровно столько, сколько нужно для заполнения цифровой матрицы. Итак, как же они получены эти 28 согласных звуков?
4 уровень. Создание звуков речи.
В современном арабском языке есть четыре особых звука. Их называют эмфатическими, хотя правильнее было бы называть их двухфокусными. При произнесении этих звуков струя воздуха, продвигаясь по речевому тракту, встречает на своем пути препятствие в двух местах. Одно – там, где это происходит при произнесении русских звуков Т, Д, С, 3, т.е. в передней части речевого аппарата. Это один фокус артикуляции. Другое – в задней части речевого аппарата, у корня языка, в гортани. Это другой фокус артикуляции. Так что при произнесении этих звуков, в отличие от всех остальных, на пути воздушной струи образуется преграда в двух местах, а не в одном, как это имеет место обычно.
Таким образом, при произнесении этих звуков используется передний фокус артикуляции и задний. Это так называемые эмфатические: (Т#) (Д#) (С#) (3#). Если мы снимем задний фокус артикуляции, останутся четыре обыкновенных звука (Т), (Д), (С), (3). Это вторая четверка звуков. Кроме того, в арабском есть еще одна четверка – четыре губных: (Б), (М), (В – произносится как английское W), (Ф). Препятствие воздушной струи при их произнесении создается губами.
Если мы выделили три бесспорные группы согласных, в каждой из которых по четыре звука, то ясно, что и остальные шестнадцать делятся на четверки. Подробное описание арабских звуковых четверок читатель найдет в мой книге "Утраченная мудрость". Здесь важно обратить внимание вот на что. Все четверки согласных получены из исходной двухфокусной четверки путем разделения фокусов и троекратного сканирования (перемещения) каждого из них вперед по речевому тракту. Так получаются семь четверок согласных. Все четверки отличаются друг от друга местом артикуляции, причем, эти места располагаются в речевой полости таким образом, что в точности копируют структуру карточной колоды, как она изображена ниже.

В чем сходство между арабскими согласными и картами?
Во-первых, как и карты, звуки речи разбиты на четверки.
Во-вторых, как и карты, звуки имеют старшую четверку, воплощающую в себе как бы два центра. В картах – это Туз. Его двухфокусность очевидна. Он является старшим среди картинок, следуя по старшинству выше короля. Он же является и старшей цифирью, поскольку, имея 11 очков, следует после десятки. В Тузе сосредоточены два центра иерархии, концы двух линий. Один – цифирный, другой – картиночный. И в этом смысле карточная колода, пусть и в замаскированном виде, построена по образцу угла, или, что то же самое, Пресвятой Троицы. Ее общий образ отличается от угла лишь тем, что в вершине угла две точки (концы двух линий) совпадают в одной, а в колоде они несколько раздвоены, хотя и совмещены в Тузе. В звуковом ряду тузу соответствует четверка эмфатических, как мы сказали двухфокусных. Все остальные четверки образуются перемещением одного из фокусов артикуляции (заднего или переднего) вперед, по ходу воздушной струи. Так что и арабские звуковые четверки, как и карты, построены по образу угла. По образу Пресвятой троицы.
Одна линия иерархии (она соответствует карточной цифири): губные (ف و م ب – Б, М, В, Ф), шипяще-шепелявые (ث ذ ج ش – Ш, Ж (дж или г), З, С ), передне-язычные (ز س د ت – Т, Д, С, 3). Фокус артикуляции последних совпадает с передним фокусом артикуляции эмфатических. Вторая линия иерархии, соответствующая картинкам: сонорные (ن ي ل ر – Р, Л, Й, Н), заднеязычные (غ ء ك ق – К#аф, Кяф, Хамза, Г#айн); гортанные (ع خ ح ه – Ъайн, и три разных X: Х5, Х8# и Х600, где в индексе обозначено место звука в цифровой матрице или, что то же самое, его числовое значение).
Таким образом, раскладка согласных звуков в полости рта такова, что последовательное перемещение каждого из фокусов артикуляции по речевому тракту как бы образует две линии, сходящиеся в группе эмфатических, т.е. эта раскладка построена по структуре Пресвятой Троицы.
В-четвертых, звуковые группы, как и карты, внешне вытянуты в одну линию, за которой скрывается угловая структура.
Что различает структуру звуковых групп от карточной колоды, так это количество групп и в целом количество карт. Но ведь карточные колоды бывают разных объемов, почему бы не быть и колоде в 28 карт? Причем, "звуковой туз" в таком случае будет иметь не 11 очков, а 9. При этом "звуковая колода" примет следующий вид.

Как бы там ни было, звуковые группы настолько плотно копируют карточную структуру, что нет проблемы дать каждой группе согласных карточное соответствие. Эмфатические соответствуют Тузу, гортанные – королю, заднеязычные – даме, сонорные – валету. Это "вельможная" линия иерархии. Она
располагается в задней части речевого тракта. Далее: переднеязычные соответствуют восьмерке, шипящие – семерке, губные – шестерке. Эти три группы согласных находятся в передней части речевого тракта. Так что мы видим, что структура согласных копирует карточную структуру. Согласитесь, что получить все эти структуры из обезьяньих рыков, более чем невозможная вещь.
Апокалипсис и звуки речи
Между прочим, когда читаешь Апокалипсис, трудно отделаться от ощущения, что в некоторых фрагментах текста описывается именно изложенная здесь звуковая структура. Судите сами.
"После сего я взглянул, и вот дверь отверста на небе, и прежний голос, который я слышал как бы звук трубы, говорившей со мною, сказал: взойди сюда... и вот престол стоял на небе, и на престоле был сидящий. И вокруг престола двадцать четыре престола, а на престолах видел я сидевших двадцать четыре старца... И от престола исходили молнии и громы и гласы и семь светильников огненных горели перед престолом, которые суть семь духов божьих, и перед престолом море стеклянное, подобное кристаллу.... и посреди престола и вокруг престола четыре животных, исполненных очей и спереди и сзади. (Откр. 4, 1-8).
Чтобы понять о чем речь, надо обратить внимание на то, что число описываемых объектов в тексте Откровения – 28, причем, 4 из них – исполнены очей и спереди, и сзади. Око по-арабски عين ъайн. Это же слово обозначает "место выхода", "глазок", "источник". Понятие "место выхода" ( مخرج махраг) в арабской грамматике используется как термин в значении "место артикуляции". Ясно, 'что речь идет о четырех двухфокусных звуках, тузовой четверке: Т#а ( ط ) , С#ад (ص ), Д#ад (ض ) , З#а ( ظ ), легшей в цифровую матрицу, как мы увидим ниже, буквой Г, т.е. ходом коня. Когда в Апокалипсисе упоминаются четыре всадника, то надо думать, что эта четверка – одна из них. В контексте отрывшегося легко читаются и престолы. Для этого арабское слово престол سدة судда, читаем как سد садд "плотина", "затор", "перемычка". Именно при создании в полости рта перемычек на пути воздушной струи и создаются звуки. Старцы, по всей видимости, идут от слова حرف х#арф "буква", (откуда, кстати, греческое графо "писать"), которое экстрасенс путает с арабским глаголом خرف харрафа "заговариваться о старце". Точка померещилась. Бывает.
Про значимость точки есть арабский анекдот. Однажды султан издал указ о переписи всего населения. Перепись по-арабски 'их#с#а (إحصاء ). Случись гак, что на указ села муха и нагадила. В аккурат над буквой X. Исполнители прочитали 'ихс#а (اخصاء ). Это слово значит "оскопление". Так вместо "переписи всего населения" получилось "оскопление всего населения". Так что с точками надо быть повнимательнее, господа экстрасенсы.
В этом контексте легко опознаются и остальные объекты. Семь светильников – это семь групп согласных. Сравните شلة шилла "компания, группа" и شعـلة шаъла "горелка, факел". Море хрустальное – это مرآة мир'а:т "зеркало", т.е. матрица, в клетках которой отражаются звуки речи. А уж громы и гласы не требуют и комментариев. За вроде бы совершенно бестолковым и фантастичным текстом – лекция по языкознанию.
5 уровень. Раскладка звуков по цифровой матрице или семь печатей книги человеческой.
Коль скоро в речевом аппарате у нас "звуковые карты", эти карты как пасьянс раскладываются по клеткам цифровой матрицы. Четверками.
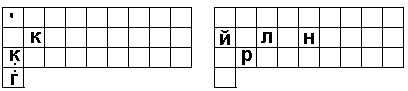
Слева раскладка губных (2, 40, 6, 80), справа – эмфатических (9, 90, 90, 800). Этих двух четверок достаточно, чтобы понять принцип. Звуки раскладываются ходом (ходами) шахматного коня.
А вот на следующем рисунке группы выложены ходом пешки (с взятием фигуры). Слева – заднеязычные (100, 100, 20, 1). Справа – сонорные (50, 30, 200, 10). Первый ход – типа е2 – е3 второй – е2 – е4, первая пешка бьет вначале направо, потом – налево, вторая – наоборот, вначале – налево, потом – направо.
Обратим внимание на то, что шахматным конем переносится в матрицу главная группа согласных, т.е. тузовая четверка, и группа, соответствующая цифирной карте, в данном случае шестерке. Что касается хода пешки, то он используется для групп, которые соответствуют картам-картинкам, т.е. карточной знати. Получается, что звуки речи при переходе в цифровую матрицу как бы меняются ролями. Вельможи во главе с королем обезличиваются, становятся пешками, а цифирь подобно Тузу въезжает в матрицу на коне. Точно как в Евангелии. Бедные попадают в рай, а богатые вельможи в ад. Туз, понятно, и в Африке – Туз.
А вот еще одна раскладка. На этот раз речь идет о группе "шипяще-шепелявых", соответствующей карточной семерке. Ход тоже конский, буквой Г, только вдвойне увеличенной.
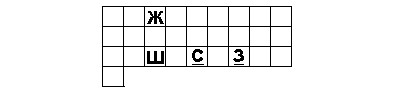
У нас остались две раскладки: "звуковая восьмерка" и "звуковой король". Эти "звуковые карты", каждая в своей линии иерархии, стоят непосредственно перед Тузом, который символизирует верховное божество, коль скоро и на этом свете, и на том он не меняет свою ипостась.
Так что же происходит с теми, кто перед Богом? Перед Богом все равны. Посмотрите на раскладки этих четверок.
Здесь каждая из них совершена смешанным ходом, конно-пешечным, рабы и знать сравнялись, как им и положено, когда они перед Богом или в бане.
Ход, что слева: пешка бьет с 7 (буква 3 – ز ) на 60 (С – س ) и затем, превратившись в коня, что она имеет возможность иногда делать, стоит перед выбором: сделать ход на 4 (Д – د ) или на 400 (Т – ت ). Такова раскладка переднеязычных.
Ход в правой матрице: пешка бьет с 8 (X# – ح ) на 70 (Ъайн – ع ) и, превратившись в коня, делает два последовательных хода: на 5 (X – ه ) и затем на 600 (X – خ ) – Такова раскладка гортанных.
Можно утверждать без большого риска ошибиться, что библейские семь печатей как раз и есть семь фигур переноса звуков в цифровую матрицу. Что касается четырех библейских всадников Апокалипсиса, то это ничто иное как четыре хода шахматного коня. А "всадник на белом коне", так это уж точно главная печать переноса тузовых согласных.
Итак, все 28 согласных нашли свои места в цифровой матрице, так что всем хватило места, и не осталось ни одной пустой клетки. Так цифры, встретившись со звуками по изложенной выше системе, превратились в буквы и образовали последовательность, которая, хотя и в искаженном виде, сохранилась во всех алфавитных системах письма: К, Л, М, Н, О, П ...
Некоторые алфавиты сократились, например, в еврейском только 22 буквы, да и то некоторые буквы пустые, сохраняются только для того, чтобы в матрице не образовались лакуны. Так, Т9 и Т400 иврита в звуковом отношении уже не различаются из-за потери заднего фокуса артикуляции. Другие алфавиты разрослись до того, что не всем буквам хватило места в матрице, из-за чего некоторые буквы остались без номеров, как в нашей кириллице. Но порядок следования букв местами сохранился, что указывает на первоисточник.
После заполнения цифровой матрицы соответствующими звуками, получаем арабский цифровой алфавит, в котором мы видим буквы в стилизованном виде (почерк насх). Здесь те конфигурации, которые пишутся отдельно, без соединения вправо или влево. Не мудрено, что теперь далеко не во всех буквах мы узнаем цифры. Даже арабские богословы, которые изучают буквы по несколько лет, не могут сообразить, что в арабском языке звуки речи просто пронумерованы цифрами.
Как бы там ни было, арабское письмо – самая простая в мире система письменности. Она до сих пор хранит в себе принципы построения алфавита. Посмотрите, Алиф ا (1), Вав و (6) и Та ط (9) легко узнаются как цифры в любых арабских почерках, тем более, что они сохраняют свои числовые значения. Хорошо просматриваются все девятки. Разве этого недостаточно, чтобы задать хотя бы вопрос, а не происходят ли и другие буквы из цифр? Но нет. Когда мозг спит, он правильные вопросы почти что не задает.
В этом алфавите вы далеко не во всех буквах увидите цифры. Это, во-первых, потому, что он выполнен почерком насх ( النسخ خط ), самым ходовым почерком, а не почерком рук#ъа ( الرقعة خط ), в большей степени отражающем связи букв с цифрами. А во-вторых, некоторые элементы цифр видоизменились из-за необходимости связывать их между собой. Вдобавок для того, чтобы видеть цифровую периодичность, надо бы сгруппировать буквы по периодам (порядкам), чего никто не делает по причине слабоумия.
Физиологическая функция алфавита
Нетрудно видеть, что в цифровой алфавитной матрице воплощены идеи не только игральных карт, шахмат, земной, бренной жизни, ада и рая, но также совмещены два календаря: солнечный и лунный. Девять месяцев беременности (девять цифр) проецируются на развертку лунного месяца, состоящего из 28 дней. Этот же цикл определяет и срок беременности (280 дней). Именно эта матрица, имеющаяся в мозгу каждой женщины, а не физическая луна, является запусковым механизмом менструального цикла, иначе у всех женщин менструальные циклы были бы синхронизированы. Об этом говорит и название первой буквы по-русски – Аз, что соответствует арабскому وز вазз "гусь", который по всем поверьям снес золотое яичко, из которого все и пошло. Эта буква и запускает механизм овуляции (появление в женском организме яйцеклетки). Причем эта же буква своим номером (числовое значение – один) вызывает красный цвет, что является командой для прилива в матку крови с целью вымывания из нее старой неоплодотворенной яйцеклетки. Подробней этот вопрос мы рассмотрим в главе "Язык и физиология".
Ноев Ковчег
Как уже было сказано здесь и более подробно в других моих работах ("Разгадка Ноева Ковчега", "Утраченная мудрость") библейское выражение семь печатей имеет в виду именно семь вышеописанных раскладок звуков по цифровой матрице. Это во-первых. Во-вторых, каждая из семи печатей может быть соотнесена с элементами судна.
Тузовая печать впереди матрицы (эмфатические) – форштевень.
– В противоположном торце печать Дамы – корма с рулевой колонкой и рулем.
– Печать Валета (сонорные РЛНЙ) – привод к рулю от двигателя.
– Печать шестерки (губные БМВФ) – иллюминаторы.
– Печать семерки (ШЖСЗ) – трюм с выходом на палубу.
– Печать восьмерки – турбинный двигатель с энергоносителем.
– Печать Короля (гортанные) – каюты Ноя и его троих сыновей.
В этом случае Ноев Ковчег и алфавитная матрица – один и тот же объект. Если для отождествления печатей с элементами судна требуется кое-какая фантазия, то размеры судна приводятся в описании Ковчега. Высота – 30 локтей, выход – 10 локтей (выход из трюма – печать ЖШСЗ), длина – триста локтей (читай три стоя, стойки, т. е. три форштевня), 3x30= 90. При всем при этом слово локти отражает не только меру длины, но и меру беременности, если слово прочитать наоборот и по-арабски ثقل ТК#Л – "тяжесть".
Число Зверя
Тот, кто знает устройство алфавитно-цифровой матрицы, иначе Ковчега Спасения, получает ключ и к пониманию сакраментального числа Зверя. Приведем здесь текст Апокалипсиса. "И он сделает то, что всем малым и великим, богатым и нищим, свободным и рабам положено будет начертание на правую руку их, или на чело их, и что никому нельзя будет ни покупать, ни продавать, кроме того, кто имеет это начертание, или имя зверя, или число имени его. Здесь мудрость. Кто имеет ум, тот сочти число зверя; ибо это число человеческое. Число его шестьсот шестьдесят шесть (Откр. 13, 16-18).
Мы знаем, что цифры-буквы в матрице кувыркаются. Кувыркаются они и при переходе из одного алфавита в другой. Ср. например, латинскую L и арабскую: لـ лям. Так что точно не известно, идет ли речь здесь о числе 666 или 999. Если же имеется в виду последнее число, то многое сходится. Эмфатические, расположенные во фронте матрицы (по-арабски фронт и чело выражаются одним словом جبهة габха), образуют букву Г (ход коня). Эта конфигурация имеет два плеча: левое и правое. Именно на правом плече три девятки (или, что графически то же самое, что и три шестерки). В тексте Апокалипсиса зверь имел два рога (Откр., 13, 11). При таком положении, как у нас на рисунке, правое плечо (рука и плечо по-арабски выражаются одним словом ذراع зира:ъ – "рычаг", "рука", "плечо") – будет длинным, с тремя кувыркающимися девятками (9, 90, 900). Становится ясным также, что искомый зверь как раз и есть арабское слово ذراع зираъ. Оно созвучно и русскому зверь и арабскому ضواري з#ава:ри ( д#ава:ри ) "звери", "плотоядные животные".
Еще об этом звере говорится, что он "имеет рану от меча и жив" (Откр., 13, 14). Это следует понимать так, что ни в одном из производных алфавитов нет эмфатических, хотя соответствующие буквы частью или целиком сохранены. В русском языке – это Еры. Хотя они не имеют числовых значений, их начертание сохраняет начертания девяток или шестерок: Ъ, Ь. Ы. Сравните с девятой арабской буквой: ط . Так что наши Еры – отражение числа зверя в русской кириллице. Обратите внимание на то, что таких букв нет больше ни в одном алфавите мира. Они существуют только в арабской и в русской азбуке. Почему это так, будет ясно позже.
Число Зверя, сказано, число человеческое. Это соответствует тому, что матрица, знаком которого является число Зверя, является механизмом управления циклами воспроизводства человека.
Положением о купле и продаже подчеркивается идея о том, что коммуникативный акт, а следовательно, и акт купли продажи, не может быть осуществлен без языка. Мудрость же числа в том, что тот, кто знает "число Зверя", получит ключ к разгадке всякой тайны, так или иначе связанной со словом, и, следовательно, перестанет жить в мире бессмысленных слов, как это происходит до сих пор со всем человечеством.
Справедливости ради следует сказать, что расшифровок числа Зверя сделано превеликое множество. Но сделаны они людьми слепыми и глухими. Берут три шестерки и сопоставляют с разными величинами. Кто считает ворота в Иерусалиме, кто сравнивает с температурой тела человека, кто подтягивает под число пи. Только мудрости из этого никакой. Одна глупость. Почему? А потому, что никто не считается с контекстом. Явный признак шизофрении. Ведь в тексте сообщается много признаков числа. Надо их все учитывать. И чело и правую руку и слово зверь, и то, что число человеческое, а самое главное, должна получаться хоть какая-то мудрость. Хоть какие-то следствия. У нас же мудрость такая. Все тайное становится явным. Все слова всех языков, Все в мире таинства, ритуалы, обряды, обычаи, секреты здоровья и болезни. Короче говоря, все, что связано со словом. А вначале ведь было слово.
Гласные
Арабские буквы обозначают только согласные звуки, гласные не обозначаются, а при необходимости сверху и внизу строки пишут специальные значки, называемые огласовками. Все огласовки ставятся только в словарях и в специальных учебных текстах. Отсутствие значков для гласных в обычном тексте отнюдь не мешает чтению. Напротив, огласованные тексты читать труднее, поскольку глаз должен прыгать то вниз, то вверх. Отсутствие огласовок компенсируется знанием грамматики.
Арабских гласных всего три: А, У, И + их долгие аналоги. Долгие гласные обозначаются в строке буквами Алиф (ا или ى ), Вав (و ), Йа (ي ).
По месту образования в полости рта гласные находятся по краям описанных выше иерархических линий сканирования фокусов артикуляции согласных, т.е. в вершине угла и на концах линий, составляющих этот угол. У – губная, И – среднеязычная и А – гортанизированная.
Едва ли не главной особенностью арабского языка является функциональное размежевание между гласными и согласными. Согласные, главным образом, связаны с передачей лексической идеи, гласные являются показателем грамматики слова, иными словами, отражают связь этой идеи к различным сторонам ее включения в контекст, ситуацию, в смысловое поле. Поскольку ситуация и контекст известны читающему, то грамматика слова в арабском тексте не обязательно должна отражаться со всей полнотой. Это и создает возможность не ставить огласовки. Они легко восстанавливаются читающим. Критерием правильности чтения является смысл. Если при прочтении того или иного фрагмента текста смысл складывается, значит, читающий восстановил упущенные огласовки правильно. Отдельное взятое слово, вне контекста, можно прочитать несколькими способами. Число таких способов иногда достигает до десяти и более. Тем не менее это не создает препятствий при чтении, если читающий руководствуется здравым смыслом.
В производных языках гласных больше. Это результат компенсации павших гортанных. Падение гортанных не только сузило звуковую базу языка, но и разрушило грамматику слова. Чтение слова без огласовок стало затруднительным или даже невозможным. Появилась необходимость введения гласных в строку как самостоятельных и равноправных участников структуры слова.
Примечательно, что буквы, обозначающие в арабском языке гортанные, в других алфавитах используются для обозначения гласных. Гортанные в арабском занимают следующие позиции в алфавите:
1 (хамза – ء ), 5 (ه
), 8 (ح ), 9 (ط ), 70 (ع
), 90 (ص ), 800 (ض ), 900 (ظ
), 1000 (غ
).
Гортанная номер 1 (хамза ء ) в арабской письменности обозначается только в специально оговоренных грамматикой условиях. Обычно она пишется совместно с Алифом (единичкой): أ или с другими "слабыми" буквами (Вав или Йа) : ؤ ئ .
Правила написания хамзы достаточно сложны, поэтому ее знак ( ء ), являющийся редуцированным знаком Ъайна ( ع ), практически нигде в новообразовавшихся языках не используется, кроме, пожалуй еврейской йоты ( י ), которая занимает позицию на клеточку ниже (10). В других алфавитах для обозначения этой гласной ( й ) используется арабский алиф с точкой ( i ).
Гортанная Ха номер 5 в арабском обозначается пятеркой (кружком): ه . В конце слова она пишется с точками, если является показателем женского рода имен: ة и произносится а(х). Придыхание иностранцами не слышится, потому создается впечатление, что это гласный А. Именно этой гортанной обозначается звук А в производных алфавитах. Все варианты этой буквы, включая и рукописные, являются ни чем иным как вариантами арабской буквы X. Сравни: ـة . Другие варианты этой арабской буквы дали в производных языках буквы о, е.
На позиции 5 в новых языках стоит гласная Е, ее конфигурация взята с позиции 70, где находится арабский Ъайн (ع ), а на месте Ъайна мы видим букву О. Видно, что произошел обмен букв между позициями 5 и 70 (О и Е поменялись местами).
На позиции 8 в арабском находится буква х#-восьмеричная: ح . На числовое значение буквы указывает ее начертание, особенно в почерке рукъа. Нижний хвост этой буквы пишется только в конце слова. Если буква соединяется и справа, и слева, она превращается в конфигурацию, точную копию которой мы видим в греческой h (числовое значение – 8 ), если смотреть на нее справа. Латинское h, следующая восьмой по счету, и наше И-восьмеричное – есть просто графические варианты той же конфигурации. Что интересно, связь этих букв с цифрой восемь прослеживается только через арабский алфавит. Вне арабского алфавита связь эта становится мистической. Это обстоятельство является еще одним доказательством первичности арабского письма.
Буква У взята от еврейского Ъайна или, что то же самое, от арабского Ъайна, поставленного на попа عـا . Буква Ю – лигатура, соединение I – десятеричного (Алифа) с О. Э от Е. Таким образом, все без исключения гласные – от арабских гортанных.
Буквы, стоящие на позициях 9, 90, 900 (число Зверя) и 800 не собственно гортанные, а гортанизированные. Все они изображаются девятками, которые хорошо просматриваются во всех арабских почерках. Падение гортанного фокуса артикуляции привело почти что к полному забвению этих букв. Сохраняется только девятая буква Тэта ( в греческом J, которая в еврейском, например, является пустой, поскольку в иврите нет двух разных Т. Сохраняется она в иврите (ט) скорее для сохранения числового ряда. К сожалению, несмотря на то, что эта буква сохраняет свое числовое значение, никто не видит в ней девятку. Не видят девятку даже в более доступном греческом алфавите: J. Эта слепота ничем не может быть объяснена, кроме как дисфункцией головного мозга филологов.
Как было уже сказано, единственный алфавит мира, сохраняющий число Зверя – русский. В древнерусском языке знаками Ъ, Ь обозначали редуцированные (слабые гласные). Эти два знака вместе с буквой Ы составляют полный ряд числа Зверя (раненого, но живого).
А вот как об этих буквах говорится в Апокалипсисе, в отрывке "Видение Господа на престоле".
" ... вокруг престола четыре животных, исполненных очей и спереди и сзади. И первое животное было подобно льву, и второе животное подобно тельцу, и третье животное имело лице. как человек, и четвертое животное подобно орлу летящему." (Откр. 4, 5-6).
Эти четыре образа точно соотносятся с четырьмя арабскими словами, которые начинаются с соответствующих эмфатических букв: ضاري д#а:ри "кровожадный, хищный", конкретное значение "лев", далее ظأر за'ра "смотреть за теленком (о верблюдице)", صورة с#у:ра – "образ, картина", طير т#айр "птица", буквально "летящая". Если знать, что и "орел" от هار ха:ра "падать вниз, лететь", "бесстрашно кидаться в бой", то комплектность четырех эмфатических налицо. Эти девятки все пали, а их знаки в русском стали использоваться для гласных. Обратите внимание на то, что все четыре арабских названия кончаются на Р. Отсюда выходит, что наши Еры – от этих названий. И по очертанию сходятся, и по названию. Все они кончаются на Р, как и исходные арабские названия: ДР, ЗР, СР ТР, и по просвечивающейся в Ерах цифре 9 ( или 6): Ъ, Ь, Ы.
Два алфавита
В настоящее время в арабском языке существует два алфавита. Оба состоят из одних и тех же 28 букв, но различаются порядком их следования. В первом алфавите под названием абгадиййа – и он исходный – буквы располагаются в порядке возрастания их числовых значений. Во втором который называется ( التهجية حروف) х#уру:ф ат-тахгиййат – буквы тахгият, буквы сгруппированы по общности написания. Он так же, как и первый, начинается с Алифа, но после второй буквы Б (ب числовое значение – 2) следует не буква Г ( ج числовое значение – 3), а буквы Т и С ( ث ت числовые значения соответственно 400 и 500), поскольку эти последние буквы имеют начертания такие же, как и буква Б. Подряд также идут буквы Гим, Х#а, Ха ( خ ح ج ), поскольку они различаются только наличием и местом расположения точки.
Понятно, что второй алфавит, где буквы сгруппированы по общности написания, – производный, является модификацией первого алфавита. Причем, если первый алфавит, пусть и в деформированном виде, отражается и в других языках (арамейском, еврейском, греческом, латинском русском), то второй существует только в арабском. Правда, он имеет одну общую черту с русским. Вместе с ним он составляет единственную пару алфавитов, которые начинаются с буквы А, а кончаются буквой Я.
Название первого прозрачно. Оно происходит от перечисления первых четырех букв алфавита.
Название второго несколько загадочно. Мотивирующий корень имеет два значения. 1. "перечислять недостатки кого-л ", "критиковать"; 2. "перечислять буквы", "произносить слово по буквам". На мой взгляд, первое значение этого корня поясняет суть. Ведь перед нами алфавит измененный, скажем, даже искаженный по отношению к первичному.
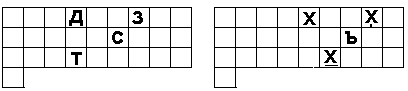
Представляет интерес познакомиться подробней с системой искажений. Если те буквы, которые группируются в одну группу, выписать в столбик, то окажется, что под первые четыре (титульные) буквы подписываются другие, имеющие с титульными общее начертание. В русском выражении это выглядит так.
|
А |
Б Т С |
Г Х Х |
Д З |
Читая по порядку столбики, получаем последовательность из первых девяти букв А, Б, Т, С, Г, X, X, Д, 3.
По-арабски : ذ
د
خ ح
ج
ث
ت
ب أ
Далее идет 6 столбиков по две буквы:
(Ра, Зайн ز ر ); (Син, Шин – ش س ); (С#ад, Д#ад – ض ص ); (Т#а, З#а – ظ ط);(Ъайн, Г#айн – غ ع ); (Фа, К#аф – ق ف ).
После пар идет ряд титульных букв без "нагрузки": Кяф, Лам, Мим, Нун. ( ن م ل ك ). Причем этот ряд КЛМН ни в одном из известных алфавитов не имеет искажения. Запомним это свойство. Оно нам пригодится в дальнейшем.
Далее идет буква Ха ( ه ), которая по начертанию одинакова с нашей буквой О, что еще раз вызывает удивление из-за совпадения в последовательности. Замыкают алфавит так называемые "слабые" Вав и Йа (Я) – ي و .
Пронумеруем столбики так, чтобы носителями номеров были только титульные буквы. В этом случае обнаруживается удивительная вещь.
10 9 8 7 6 5 4 3 2 1
ف ع ط ص س ر د ج ب ا
ق غ ظ ض ش ز ذ ح ت
خ ث
17 16 15 14 13 12 11
ي و ه ن م ل ك
Во втором алфавите при новой раскладке
всего титульных букв будет 17. Причем, они выстраиваются в два периода. Один
период – сжатый, второй – обычный.
Теперь мы видим, что буквы первой четверки (А, Б, Г, Д) в новом алфавите стоят на своих местах (1, 2, 3, 4). То же по отношению и к четверке КЛМН – ن م ل ك . Она занимает соответственно позиции 11, 12, 13, 14 Точно такие же, какие она занимала в счетном алфавите! Вряд ли это случайность. Ведь при обычной раскладке нового алфавита эти буквы занимают позиции 22, 23, 24, 25.
Пожалуй, заслуживает внимание еще то, что данный буквенный ряд закольцован. Он кончается буквой Я ( ي ) , которая может быть помещена в один столбец с буквой Алиф максура (ى ), которая является, как было сказано в предыдущей главе, русским Алифом (гусем), что явным образом, напомню, отражается в названии (маКСУР – РУСК).
Что же произошло с алфавитной матрицей? А произошло ее сжатие. Вместо трех полос матрица сжалась до двух неполных. Но что характерно, начальная четверка согласных, как оказывается после снятия "камуфляжа", остается на своих позициях. То же и по отношению к четверке согласных КЛМН. Она осталась во втором периоде и на своем месте. Забегая вперед, скажу, что эта четверка согласных выполняет особую функцию в физиологическом механизме воспроизводства человека. В частности, буквы МН занимают 13 и 14 позиции, что соответствует 13 и 14 дню менструального цикла. Это наиболее благоприятные дни для зачатия, поскольку корень МН образует слово منى мана: "сперма". Чтобы зачатие произошло, сперма должна попасть на свои клеточки. Подробности будут описаны в главе "Язык и физиология". Сейчас нам достаточно знать, почему порядок и место букв КЛМН не меняется.
6 уровень. Лексико-грамматическое развертывание языка (арабского).
Словообразование и синтаксис описываются в нормативной грамматике, которую я подменять не собираюсь. Но общие принципы словообразования на начальных этапах развертывания ее, в особенности не описанные в грамматиках, упомянуть следует.
1. Корень и словообразование. Арабский корень имеет жесткую структуру и обязательно включает три согласных, которыми выражается некая идея, предположим, открытия (корень ح ت ف ФТХ#). Имеется также система четырехсогласных корней, однако она менее распространена по причине ее слабой мощности в смысле словообразования и ограниченных семантических возможностей. Ее мы здесь касаться не будем.
Огласовки корневых согласных, часто совместно с
дополнительными, некорневыми согласными, выражают грамматику слова, т.е.
отношение данной идеи к описываемой словом ситуации, ее участникам и ее
параметрам, таких как время, модальность, залог и т.п. При этом гласные, если
нет особой необходимости, на письме не обозначаются. Вследствие чего все эти
формы слова пишутся одинаково:
|
|
ФаТаХ#а |
"он открыл", |
|
|
ФуТиХ#а |
"он был открыт" |
|
|
ФаТХ# |
"открытие" |



Контекст
позволяет легко отличить одну форму от другой.
Глаголы, основа которых состоит только из корня, называют непроизводными, или глаголами первой породы. От первой породы образуются глаголы производных пород. Всего пород – 15. Но обычно в нормативные курсы включаются только десять наиболее распространенных пород.
Производные породы образуются путем внедрения в состав слова аффиксов (некорневых морфем) либо удвоением средней корневой (вторая порода), либо удлинением первой огласовки (третья порода). Пример образования второй породы от первой: فتح фатах#а "он раскрыл": فتح фаттах#а "он пораскрывал". Пример образования третьей породы от этого же корня: فاتح фа:тах#а "он раскрыл себя кому-то, он признался".
От глагола первой породы можно образовать имя действия (масдар), имя деятеля (причастие действительное), имя поддейственного (причастие страдательное), имя орудия, имя времени и места, имя способа совершения действия, имя остатка, имя болезни, и некоторые другие имена.
От глаголов производных пород образуется имя действия (масдар), оба причастия и иногда имя места (совпадающее по форме с причастием страдательным). Большинство арабских слов относятся к одной из перечисленных здесь категорий. Каждая из них имеет особую формулу образования. Например, مفتاح мифта:х#, "ключ" – является именем орудия первой породы корня ФТХ# "открывать", فاتح фа:тих# "открывающий" – причастием действительным этой же породы. Соответствующая формула определяется по конфигурации огласовок и по включенным в слово некорневым согласным. Основу всего словообразования составляет система пород.
2. Типы корней и корнеобразование.
Арабские корни подразделяются на сильные и слабые. Слабые – это такие, что содержат в своем составе слабые согласные (полугласные). Это Й – ي и В – و (напомню, произносится как английское W). К их числу можно отнести и Хамзу, поскольку этот звук так же как и слабые вносит в формулы определенные изменения.
В зависимости от места слабой в корне, корни подразделяются на
– подобноправильные, если слабая занимает первую позицию, например, وصل вас#ала "прибывать";
– пустые, если слабая занимает вторую позицию, например, корень كون КВН "бытие";
– недостаточные, если слабая занимает третью позицию в корне, например مشي МШЙ "идти".
Наличие слабой в корне сильно модифицирует формулы словообразования, о которых шла речь выше, но по довольно жестким правилам. Слабые согласные, в зависимости от модели слова, могут редуцироваться до гласных, долгих или даже кратких, и, следовательно, как и любые краткие гласные, могут не обозначаться на письме. Слабые могут переходить друг в друга или в хамзу, тоже, впрочем, по определенным правилам. Так, глагол от كون каун (каwн) "бытие" в прошедшем времени пишется и произносится كان ка:на "он был", где корневой Вав подменяется Алифом; повелительное наклонение для второго лица мужского рода пишется только в две буквы: كن кун "будь"; в причастии действительном слабая Вав подменяется Хамзой: كائن ка:'ин. Как видим, в разных формах слова слабая то появляется, то исчезает, то вновь появляется, но уже под масками других букв.
Около полутора тысяч арабских корней, что составляет примерно четверть всех имеющихся, – слабые. Именно от них образуются наиболее употребительные слова, так что по меньшей мере каждое третье слово в тексте образовано от слабого корня и поэтому маскирует место и качество слабой корневой. Это обстоятельство значительно затрудняет чтение арабского текста и даже нахождение слова в словаре. Большинство арабских словарей составлено по корневому принципу. Все слова от одного корня помещаются в одной статье, иначе, слова группируются в алфавитном порядке корневых согласных. Тот, кто читает текст на арабском языке, постоянно ведет анализ слов с точки зрения состава его корневых согласных. Критерием правильности такого анализа является складывающийся смысл читаемого. Если смысл не сложился, значит где-то ошибка, либо в определении огласовки, либо в определении корня.
Все, что было здесь сказано о корнях и о словообразовании, можно найти в любой грамматике арабского языка. Но вот как образуются сами корни – этот вопрос до сих пор оставался не выясненным, хотя попыток в этом направлении было предпринято немало. Еще в раннее средневековье арабские грамматисты пытались представить значение корня как сумму значений корневых согласных, предполагая, что каждая согласная имеет свое собственное значение. Далее нескольких правдоподобных Примеров дело не пошло. К счастью, арабы быстро сообразили, что идут по тупиковому пути, и не стали строить на этом болоте эзотерическую теорию, хотя поводы для того в арабском можно найти гораздо более основательные, чем в еврейском, где выстроено бестолковое учение под названием каббала, и в русском, где подобные теории сейчас, после развала нашей мафиозной науки, державшей в прежние времена все в ежовых рукавицах, стали расти как грибы.
Ошибка арабов состояла в том, что они видели лишь механическую сумму сложения, не замечая, что кроме сложения, в корне происходят процессы свертывания. Чтобы пояснить, о Чем идет речь, возьмем, к примеру, корень КВМ, от которого в арабском كومة ку:ма "куча". Образуем от него путем удвоения среднего корневого глагол второй породы: كوم каввама "нагромождать, сваливать в кучи", "накапливать". Теперь вставим в корень согласный Р, имеющий то же значение, что и вторая Порода. Получается корень ركم РКМ "сваливать в кучи", "накапливать". Поскольку в корне только три места, слабый согласный Вав свернулся. Кажется, что его нет. На самом деле за РКМ стоит Р + КВМ. И едва мы отделим Р, снова в корне появляется слабый. Арабы этого не учитывали, и потому при попытке отделить некоторые буквы в остатке у них оставался двухсогласный корень КМ. Такой механический подход и не позволил им вскрыть механизм корнеобразования.
Не заметили арабы и того, что список аффиксальных согласных, а его выявить не трудно, если знаешь принцип, в целом семантически копируют систему пород, что значительно облегчает их выявление. Взятый нами согласный Р по значению точно соответствует второй (интенсивной или каузативной породе). Так и другие аффиксальные согласные, внедряющиеся в корень. Их около десяти. Р (ر ) соответствует второй породе, Д (د ) – третьей или шестой, X# ( ح ) – десятой и т. д.
Но что интересно. Если в начале процесса наращивания аффиксальных согласных, мы имели корень, состоящий, предположим, из одних только слабых, то все корневые постепенно, один за другим, могут быть вытеснены аффиксами, в результате мы получим корни, целиком состоящие из аффиксов, но значения полученных корней вытекают не столько из значений аффиксов, сколько из значения первичного корня. И это несмотря на то, что ни одного корневого в явном виде в корне уже нет.
Такой пример. Идея округлости, вращения, поворота выражена в корне وراء вара:' "назад". Причем, по всей видимости, Р здесь просто усилитель, а корень тот же, что в русском вить. Корень принимает аффикс Д и превращается в دور ДВР, от которого глагол первой породы دار да:ра "вращаться", "поворачивать". От него образуется десятая порода: استدار 'истада:ра "становиться круглым". Функцию внешнего аффикса ист – выполняет внутренний X# ( ح ), Механически заменяем аффиксом X аффикс десятой породы 'ист, получаем корень حدر Х#ДР "становиться круглым". Итак, постепенным внедрением в корень один за другим аффиксов Р, Д, X# получен корень Х#ДР, состоящий из одних только аффиксов, однако главный стержень в значении данного корня, идея округлости, остался, хотя ни одного корневого здесь нет. Корень вить как бы исчез или свернулся. Но только формально, в звуковом отношении. Семантически он продолжает присутствовать в полном объеме и именно он определяет, главным образом, семантику слова. Аффиксы вносят в корень лишь дополнительные оттенки, которые, кстати, по причине своей малозначимости могут легко десемантизироваться, выветриться в реальном употреблении слов. Так, в приведенном примере значение интенсивности в аффиксе Р стерлось. Уже в глаголе دار да:ра этой семантики нет. Ведь глагол обозначает не только интенсивные вращения, но любые, и даже вялые.
При всем этом необходимо учитывать, что обогащение корней семантикой (значениями) происходит не только и не столько в результате их аффиксальной обработки, сколько в реальном употреблении в речи. Предположим мы обозначили неким словом некую вещь, исходя из того, что значение слова отражает какой-то броский признак вещи. Ну, например, птицу, известную своей клептоманией, назвали "воровкой", что по-арабски называется سروقة сару:к#а, т.е. сорока. Но так не бывает, чтобы у вещи был один всего лишь признак. И тут дело в том, что слово сорока потенциально уже обозначает не только клептоманию, но саму вещь как таковую вместе со всеми ее признаками. Говорят: трещит как сорока. За сорокой теперь уже не воровство, а совсем другое качество. Как в телекамере луч снимает потенциал с освещенной так или иначе ячейки фотоэлемента, так и слово снимает признаки с реальных (или вымышленных) вещей.
В слове надо различать этимологическое значение и коммуникативное. Этимологическое значение – это то, которое явилось причиной приложения данного слова к данной вещи. Оно у слова одно. Коммуникативные значения – это те значения, которые указываются в толковых и двуязычных словарях. Их обычно много. Почти все они – результат либо переосмысления исходного этимологического, либо это значения, снятые с реальности. Малина, вероятно, названа по мягкости, (от арабского ملين мулаййан "размягченный" или мали:н "мягкий", поскольку эта ягода легко уминается, Но вот малиновый уже означает не "мягкий", а "цвета малины" или "приготовленный из малины".
Здесь важно понять, что каждый раз, когда в дело вступают аффиксы, они обрабатывают корень и вступают во взаимодействие не обязательно с тем значением, которое идет именно от корня, но и с благоприобретенными значениями, и, главным образом, с ними. У нас собака названа по функции, по ее использованию в собачьих бегах (от سباق сибак# "гонки"), но собачиться – это совсем не участие в бегах, а нечто другое.
Кроме аффиксального способа корнеобразования имеется другой, называемый в специальной литературе аллотезой. Имеется в виду изменение звучания слова, в частном случае изменение звучания какой-нибудь согласной корня. На русском материале: кристалл, хрусталь. Это явление можно найти в любом языке, но в арабском оно представлено в более массовом виде и касается только согласных корня. Как правило, отклонение звучания, если это действительно аллотеза, происходит в пределах гоморганности звука. Т.е. произношение меняется, но произносится слово тем же органом речи, например, губами. Если аллотеза сопровождается изменением значения, то этот процесс имеет непосредственное отношение к корнеобразованию. Загадочным это явление не представляется и дело здесь лишь за тем, чтобы бы в этимологическом исследовании оно было учтено.
Если из общего количества корней арабского языка мы постепенно будем изымать корни производные (по мере их выявления), то в постоянно сужающемся круге корней мало помалу начинает проявляться тот исходный принцип генерирования корней, который нас должен привести к началу.
Выясняется вот что. Сколько бы мы ни извлекали аффиксов из состава корня, в остатке никогда не получается менее трех согласных. Этот эффект объясняется двумя факторами. Первый – восстанавливаются свернутые слабые. Второй состоит в том, что в арабском языке любой звуковой материал, даже состоящий всего лишь, на наш взгляд, из одной гласной, автоматически становится состоящим как бы из трех согласных, если только он мыслится в качестве знаменательного слова.
Поясню на примере. Предположим, звучит гласная А, передающая некую идею. В этом случае переход от "незвука" к звуку, т.е. само начало произношения, воспринимается как согласный хамза. А схождение звука на нет становится придыханием, т.е. звуком Х5 ( ه ). Что же касается самого гласного звука, то он воспринимается как долгий, независимо от реальной долготы звучания, поскольку в закрытом слоге любая долгота произносится кратко. В свою очередь, за любым долгим мыслится слабый (Вав или Йа). Итак, заимствовав, допустим, из какого-то языка слово а, арабский язык автоматически превращает его в трехсогласный комплекс, не меняя его звучания. Причем, и записывается это слово в три знака: آه (в транскрипции: 'а:х).
Далее выясняется, что базовые корни группируются
вокруг согласных, которые назовем опорными. Это, как правило, согласные
передние. При произнесении этих согласных так, чтобы при этом рот раскрывался,
они образуют корни, означающие раскрытие, расширение, распространение и т.п.
Если же эти же согласные произносить наоборот, т. е. с закрытием речевого
аппарата, то образующиеся при этом корни означают нечто противоположное,
"закрытие, сужение". В арабском языке я нашел около 50 пар корней,
прекрасно иллюстрирующих это положение. Вот на русском материале: от – до ( с закономерным сопутствующим оглушением
на конце от), зев(атъ) – вяз(ать). На арабском: ضم д#амм "стягивать", مد мадд
"растягивать". Затем эти корни обрабатываются различными аффиксами, а
также происходят их изменения по принципу аллотезы. Значения корней постепенно
уходят от первоначальных (например: расширяться > распространяться >
расходиться > путешествовать; другая линия развития от этого же корня:
расширяться > разжижаться > жижа > грязь > плохо, считать плохим
> ругаться). Эта схема воплощена в конкретном звучании СА. В конце
первой линии развития стоит русское сваха из выражения переезжая
сваха, где на самом деле не сваха, а арабское слово سواحة савваха
"путешественник"; в конце второй лини – русское сетовать,
производное от арабского استاء иста:'
"сетовать" (восьмая порода от
سوء са:' "быть плохим",
откуда سوء су:', "плохость" и
откуда в русском суеверие, суета. Но разве скажешь, что все эти
русские слова – родственники, если видишь лишь вершины корневых связей? Разве
скажешь, что в сетовать звук т не является корневым? Тем не
менее, все эти шаги эволюции семантики и звучания Достаточно точно
прослеживаются на арабском материале вплоть до самого начала. А в начале
процесса корнеобразования, как было сказано, лежит звукоизображение. СА
– расширение, АС – "сужение", ср. русское ось (довольно
близкий родственник сетовать).
Речевым аппаратом в начале корнеобразования изображается то, на что похоже обозначаемые вещи. А изображаются пульсации, переходы от точки к окружности и наоборот, изображается символ развертывания точки в окружность, если хотите, ипостась Пресвятой Троицы. Ведь, рассмотренный в начале угол – есть лишь момент развертывания точки в шар. Именно по этой схеме разворачивается корневая система арабского языка.
При реконструкции корневой сети выясняется также, что все корни родственны. Понятие корня, как некоего застывшею звукового комплекса, как это принято в языкознании, не имеет смысла. Корневая система языка больше напоминает корневую систему дерева, где корни не точки (глазки), а связи, жилы, имеющие ответвления. И все эти ответвления, в конечном итоге, сходятся в одной точке, в точке начала, в точке нуля. Кстати, в Вавилоне нуль изображался окружностью с точкой в его центре.
Однажды я решил посмотреть, как далеко заходят родственные связи слов в русском языке, языке явно производном в своей основе от арабского. После того, как через посредство арабского языка в родственные отношения были поставлены более тысячи русских непроизводных слов, т.е. таких, которые не имеют явного родства со словами других корневых гнезд, я понял, что корневое родство – тотальное свойство и русского языка.
Таковы некоторые особенности структуры арабского языка, половины ядра кристалла общечеловеческого языка.
7 уровень. Развертывание этнических языков. Этногенез.
Механизм глоттогенеза
Схема развертывания языкового разнообразия весьма напоминает таблицу химических элементов по Бору (10, т. 19, с. 415). Таблица Бора отличается от таблицы Менделеева тем, что отдельные внешние строчки помещены во внутрь таблицы, так что общий вид таблицы Бора напоминает веер, в вершине которого две точки: Гелий и Водород. Гелий держит линию инертных газов, а водород как бы распадается веером на остальные элементы, заполняющие таблицу. Первый период таблицы точно соответствует солнечной плазме, состоящей, как известно, главным образом, из водорода и гелия. Совокупность двух языков, арабского и русского, я бы назвал языковой плазмой, где гелию соответствует арабский язык, мало меняющийся и консервативный, чуждающийся заимствований, а водороду – русский, подвижный, с размытой грамматикой, легко взаимодействующий с другими языками.
Уже в структуре арабского языка заложен механизм глоттогенеза (образования языков) и, соответственно, этногенеза. Почти треть арабских согласных произносится слабоуправляемыми задними органами речи, что объективно создает предпосылки к их падению (по закону экономии усилий) и замещению передними звуками, объективно более простыми в произношении, поскольку они произносятся подвижными и тонко управляемыми органами речи (языком, губами).
Любая группа людей, выходя из орбиты влияния арабских традиций и установлений институтов арабского общества, упрощает произношение звуков, что приводит к структурным деформациям, (вспомним библейский образ зверя, который имеет рану от меча и жив). Эти деформации затрагивают структуру корня и, следовательно, всю грамматику слова. После падения гортанных корень перестает быть трехсогласным, гласные застывают и сливаются с корнем, теряя свою грамматическую функцию. Теряя грамматическую жесткость, язык становится более терпим в отношении заимствований, что еще более разъедает первоначальную структуру языка. Падение гортанных компенсируется, к примеру, развитием звуков передней артикуляции. Слова все более удаляются от своего первоначального звучания.
Похоже, что первым языком, утратившим гортанные, был русский. Подвергнувшись изменениям, он показал другим языкам путь к изменениям. Так по этой схеме постепенно образуются все новые языки.
Письменности
В соответствии с тем, что регионов было семь, было создано семь письменных систем. Письменности для других народов создавали русские, и следы кириллицы мы можем наблюдать во всех системах письма.
Первый регион стал пользоваться уставным алфавитом Устав от арабского استوى 'истава: "быть ровным" Распространившиеся по свету руны – это тоже уставное письмо, от русского ровное. Особенность уставного (рунического) письма состоит в том, что его буквы складываются по преимуществу из прямых палочек, которые являются ни чем иным как единичками.
Второй регион, идеология которого строится на маске, поскольку два этимологически того же корня, что и скрывать, скрывает кириллические и арабские буквы-цифры, как и лики своих богов, за масками. Мало того, что многие маски-буквы сохраняют начертания кириллических букв, их маски во многих случаях, как показали наблюдения Пономарева В.А., подбираются на основе русского языка. С – скоба, 3 – змея, М – сова (мудрость) и т.д. Таким образом, каждая буква, имея маску, несет на себе идею двойки, номера региона.
Третий регион, Индия, как мы уже знаем, изображается на древнеегипетской фреске о сотворении мира небесной коровой, рожающей звезды и солнце. В ознаменовании этого обстоятельства, индусы для обозначения буквы А взяли древнеегипетскую фреску.
|
|
|
|
Древнеегипетская небесная
корова Нут, рожающая солнце и звезды (слева) и индийская буква А письма
деванагари. Справа – буквы деванагари. Видно, что индусы пишут
одними коровами, т.е. одними тройками, используя непрестанно меняющуюся букву
гимель. |
|
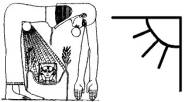

Что же касается начертания остальных букв, то все они являются вариантами небесной коровы, рожающей звезды. Сравните египетскую фреску небесной коровы и букву А письма деванагари, а также другие буквы этой письменности.
Если разум открыт, совсем не надо владеть психотехникой йогов. Последним же не помогает и психотехника. Обратите, между прочим, внимание, откуда растут у Нут руки. То-то же. К теме головы мы еще вернемся.
Таким образом, любая буква письма индусов есть просто тройка, или небесная корова. Священные коровы, бродящие по дорогам Индии по никому из йогов пока не известной причине, это те же буквы.
Индийское письмо называется Деванагари. Никто не знает, что означает это слово. На самом деле название индийского письма есть сложение арабского даввана "писать" и гари "чтец". Эти же понятия в именах сестер, создателей египетского письма Сешет и Мефдот. Первое имя от русского корня чит-ать, т.е. считывать, второе – от арабского مفيدة муфи:дат "сообщение". Эти же понятия в именах братьев Кирилла и Мефодия. Кирилл буквально значит "чтец божий", Мефодий, как и Мефдот, от арабского муфи:дат "сообщение", т.е. "письмо".
В нашем представлении Мефодий жил тысячу лет назад, древние египтяне считали, что Мефдот даже для них жил в давно прошедшем времени.
Четвертый регион стал пользоваться квадратным письмом. Это видно не только потому, что есть особые "квадратные" почерка, а, главным образом, потому что буквы-цифры создаются движением квадратной точки. Кроме того большинство букв имеют различительные точки, а все они квадратные, так что арабский текст становится весь усеян квадратиками, символизирующими их Каабу, которую не перестают созерцать обходящие ее арабы Квадратиков в тексте им мало.
Пятый регион, как кажется, не оставил нам следов своей исконной письменности.
Шестой регион, занимавшийся размножением, получил письмо, в котором так много букв, что нельзя не вспомнить о механизме размножения, завязанным на шестерку, ср. six – sex Это несмотря на то, что базовых элементов для строительства бесчисленных иероглифов всего 28. Ровно столько, сколько букв в арабском.
Седьмой регион строит свои буквы исключительно из семерок-клиньев. Других знаков не признает. Шумеры словно боятся, что их номер может остаться незамеченным.
Эволюция цифр
Чтобы представить себе эволюцию цифр-букв во всех деталях и проследить при этом процесс превращения арабских حركات х#аракатов (огласовок) в самостоятельные characters, рассмотрим эволюцию этой системы побуквенно.
Начнем с единицы.
- 1. Варианты арабской единицы и Алифа, единственной в мире первой буквы, совпадающей с единицей, чего как бы никто не замечает. 2. Римские цифры. 3. Китайские цифры, ясно сохранившие в своем начертании угол. 4. Кириллическая i десятеричная (слева), состоящая из единицы и арабского нуля.
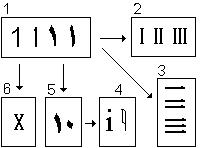
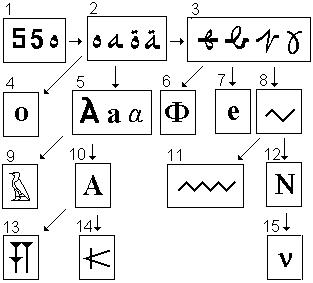
5. Арабская десятка в сравнении с русской i десятеричной. 6. Римская десятка, составленная из двух единиц-алифов. Удвоение знака – один из способов перехода буквы-цифры в высший разряд, что можно будет наблюдать на примере русской рукописной X (числовое значение -600), состоящей из двух С (числовое значение – 60).
Первоначальная двойка состояла из двух углов. Ее метаморфозы можно проследить на рисунке.
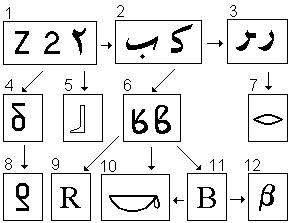
1. Варианты написания арабской двойки. 2. Арабские буквы Б (слева) и К (справа), имеющие числовые значения соответственно 2 и 20. 3 – арабская буква Р (200), ее правый вариант пишется тогда, когда нет соединения справа. В цифровой матрице буквы Б, К, Р занимают вторую колонку и потому являют собой откровенные двойки, хотя и сами арабы об этом не догадываются. Нечего и говорить, что в других алфавитах эти двойки еще более отошли от прототипа. Их узнать можно только зная систему. Вот, к примеру, на четвертой позиции в нашей схеме стоит русская буква б. То, что это перевернутая двойка, не может вызвать сомнений, но беда в том, что наша вторая буква давно уже не имеет числового значения, так что никому и в голову не приходит искать в ее начертании сходства с двойкой. 4. Русская буква. 5. Древнеегипетская буква Б под маской сапога или ноги, на самом деле являет собой перевернутое изображение арабской скорописной двойки (первая справа под номером 1). 6. Арабская лигатура, соединение Кяфа (20) и Алифа, справа – ее скорописное начертание. 7. Древнеегипетское Р, происходящее от арабского Р, замаскированное под русскую маску Рта. 8. Финикийское Б, идущее от нашего. 9. Латинское R , являющее собой перевернутую арабскую лигатуру с числовым значением 20. 10. Древнеегипетское К, идущее от арабской лигатуры (№6), под русской маской Ковша. 11. Кириллическая В (числовое значение – 2) или латинская В, идущая от той же арабской лигатуры.
Рассмотрим превращения тройки.
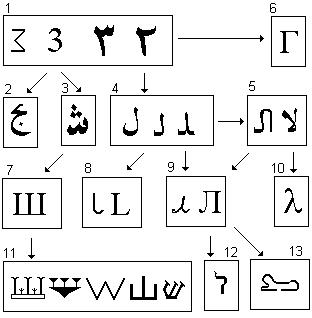
1. Варианты написания арабской тройки. 2. Арабский Гим с числовым значением – 3. 3. Арабский Шин (300). 4. Арабский Лям (30) в трех вариантах написания в зависимости от его позиции в слове. 5. Лигатуры (соединения) букв Ляма и Алифа, слева – артикль эль в скорописи, справа – слог ля. 6. Кириллическая Г (числовое значение – 3) идет прямо от скорописной арабской тройки. 7. Наша Ш, идущая прямо от арабского Шина. 8. Финикийская (слева) и латинское L, происходящие прямо из арабского ляма-тройки или кириллической Г. 9. Кириллическое Л. 10. Древнегреческая Лямбда. 11. Слева направо: древнеегипетский Ш, шумерский слог Ша, финикийская Ш, китайский иероглиф Шань (горы), древнеарамейский Шин/Син. Взять букву Ш из древнегреческого мы не могли, поскольку ее там нет и никогда не было по причине отсутствия в древнегреческом звука Ш. 12. Еврейский (древнеарамейский) Лямед, явно идущий от кириллической буквы Люди. 13. Древнеегипетская Л,
происходящая от кириллической Люди, и носящей, как и многие другие буквы древних египтян, русскую маску, изображающую Льва.
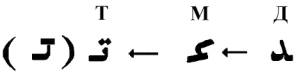
Четверка имеет ясные воплощения на всех трех этажах Ноева Ковчега. 4-40-400 > Д – М – Т:
Посмотрим, как она воплощается в других системах письма.
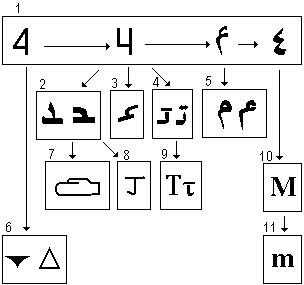
1. Варианты написания арабской четверки. 2. Арабский Даль, о числовом значении которого говорит его начертание. 3. Арабский Мим почерка рукаа (в середине слова) с числовым значением 40. 4. Арабская буква Т с числовым значением 400. Все три буквы (Д, М, Т) занимают четвертую колонку цифровой матрицы. 5. Арабский Мим в отдельном начертании. 6. Шумерский клинописный Да (слева) и греческая Дельта. Оба знака восходят к проточетверке с четырьмя углами. 7. Древнеегипетская Д, в точности повторяющая очертания арабского Даля, но, как и многие другие египетские буквы, замаскирована русской Дланью. 8. Китайский иероглиф Дзень "взрослый". Происходит от арабского Даля или прямо из четверки. 9. Греческая Тау, в строчном варианте которой легко узнается цифра четыре. 10,11 – Латинские буквы М. Самую богатую историю имеет цифра 5.
1. Варианты написания арабской пятерки. 2. Варианты написания арабской пятой буквы Ха в конце слова. Она же (с точками) показатель женского рода имен (Та марбута). Произносится а(х), в диалектах о(х) или е(х). 3. Варианты арабской Ха в середине слова. 4. Русская О. 5.Варианты русской буквы Аз. 6, 7. Буквы Ф (числовое значение 500) и Е, идущие от разных вариантов пятой арабской буквы. 8. Арабский скорописный Нун (числовое значение – 50), происходящий от пятой буквы. 9. Древнеегипетская А, происходящая от русского Аза, замаскированная русской маской "Арла" (Пономарев). 10. Вариант прописного Аза, используемый и в настоящее время. 11. Древнеегипетская Н. 12. Кириллическая, древнегреческая и латинская N. 13. Шумерский клинописный слог А. 14. Финикийский Алеф, который по недоразумению, специалисты сближают с изображением бычьей морды. Он явно происходит из кириллицы. 15. Греческая Нью.
Рассмотрим эволюцию шестерки.
1. Арабская шестерка. 2. Варианты шестой арабской буквы Вав (числовое значение – 6). От него происходит наша запятая,
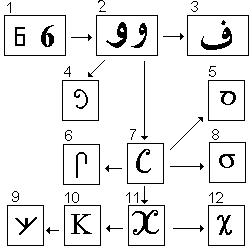
поскольку Вав в арабском является сочинительным союзом. 3. Арабская буква Фа (80). Происходит от Вава по созвучию. 4. Древнеегипетский Вав под русской маской Уха. 5. Древнеарамейская (древнееврейская) буква самех. 6,7. Древнеегипетская (под маской Скоба) и русская С, первоначальное числовое значение которой было 60, как у арабского Сина. Ныне она имеет числовое значение 200, поскольку сдвинута на одно место от места Шина, которое оно занимает, ср. арабский ряд, передающий исконный порядок,: Р, Ш, Т (200, 300, 400). 8. Древнегреческая Сигма, которая вместе с еврейским Самехом отли-чаются от кириллического Слова, главным образом, величиной "животика" шестерки. 9,10. Финикийский и кириллический К, происходящие от рукописного русского X. И. Русский рукописный X (600), являющий собой удвоенную С (первоначально 60). 12. Древнегреческая Хи.
Эволюция Семерки.
1. Протосемерка и ее упрощенные варианты написания. 2. Седьмая арабская буква Зайн (числовое значение – 7). 3. Древнеарамейский и древнееврейский Заен. 4. Арабский Айн (70) в начале слова, давший нашу букву 3 (7). 5. Арабский Айн в отдельном написании с хвостом. 6. Кириллическая Буква 3. 7.
Буква Зед в западных языках. 8. Наша Е и греческая Епсилон, происходящая по созвучию от Айна (хамзы) после его падения.
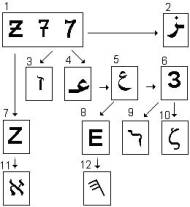
9. Древнеегипетская 3 под русской маской Змеи. 10. Древнегреческая Дзета (числовое значение – 7), идущая от Айна (70). 11. Древнеарамейский (он же древнееврейский) Алеф происходящий, возможно, от хамзы, стоящей в арабском алфавите на первом месте, и идущей по начертанию от Айна, но, возможно, прямо от нашей буквы X, поскольку еврейский Алеф произносится как придыхание. 12. Пятая буква финикийского алфавита, произносимая как придыхание. По конфигурации происходит от Айна. Исконный кружок пошел на место Айна и стал в современных алфавитах буквой О, а Айн перешел на место кружка и стал в современных алфавитах буквой Е.
Зная, что приключилось с арабским Айном, мы можем получить весьма любопытные результаты по этимологии некоторых слов. Как вытекает из изложенного, эта арабская буква в других алфавитах сохранилась в виде следа, то в начертании буквы О, то в начертании буквы Е. Если некоторые Е или О в словах русских, латинских, греческих и других читать арабским Айном, будем получать соответствующие арабские слова. Возьмем, к примеру, якобы латинского происхождения слово ЭЛЕМЕНТ. Его старшее значение в латыни – «знак алфавита". Если считать, что первая буква – арабский Айн, а именно так он и пишется в арабском языке, то получим арабское слово ъала:ма(т) "знак". Это слово того же корня, что и вышеупомянутый вавилонский остров познания Тельмун, где второе Е тоже надо читать арабским Айном. Можно взять и индийское слово ВЕДЫ. Считаем, что второе Е – арабский Айн. Знаете, что означает этот арабский корень? Он означает буквально ЗАВЕТ. Вы полагаете, случайно священные книги иудаизма, христианства и буддизма называются одним именем?
Обратимся теперь к восьмерке.
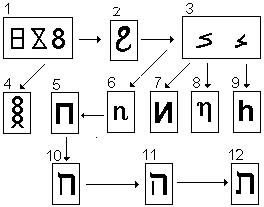
1. Протовосьмерка и арабская цифра 8. 2. Восьмая буква арабского счетного алфавита Ха (числовое значение – 8). Нижнее ее кольцо приспособлено под типичный хвост, который при соединении с последующей буквой не пишется. 3. Варианты написания арабской восьмой буквы в середине слова. 4. Древнеегипетская X. 5. Кириллическая П (числовое значение 80), восходящее через рукописное начертание к русской И восьмеричной, или прямо к арабской Ха восьмеричной (№3). 7. Кириллическое И восьмеричное, не имеющее, как кажется, аналогов в других алфавитах. 8. Греческая Эта (числовое значение – 8) и латинская Аш, занимающая восьмое место. 9,10,11. Буквы древнеарамейского алфавита Хет (8), непосредственно копирующая наше П, Хей (5), происходящей от предыдущей по созвучию (П), и Тав, происходящей от Хей по функциональной схожести (как арабская Ха и Та марбута).
Зная превращения восьмерки, можно получать этимологические результаты не менее удивительные, чем те, о которых говорилось в случае Айна. Во многих случаях ДОСТАТОЧНО наше И восьмеричное прочитать арабским X восьмеричным, как смысл непонятных слов и выражений проясняется, чему немало примеров читатель найдет в этой книге.
Самый близкий пример: наше слово письмо. Если его читать по-арабски справа налево с учетом превращения И восьмеричной, получим арабское слово МС#Х#Ф, которым обозначают Коран, Священное Писание мусульман. Оно образовано от корня С#Х#Ф "ПИСать".
Эволюция девятки.
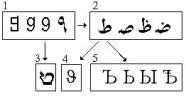
Мы подошли к последней арабской цифре, символизирующей эмбрион человека, последний месяц развития разума во чреве матери. К девятке восходит вся четверка эмфатических, изображенная под номером 2. Их числовые значения слева направо 9, 90, 900 и 800. Последняя буква Дад не вместилась в правое плечо шахматного хода и располагается в восьмой колонке, но по звуковому подобию сохраняет начертание девятки.
Девятая буква арабского алфавита является откровенной перевернутой арабской девяткой, чего по какой-то причине не замечают и сами арабы. Понятно, что евреи тем более не видят в своей букве Тет (№ 3) никакой девятки, а уж про греков и говорить не приходится. А между тем и греческая Тэта J (№ 4) сохраняет числовое значение 9, да и по начертанию от девятки практически не отличается. А если до сих пор этого никто не заметил, так это от слепоты рассудка.
В приведенные здесь схемы эволюции цифр в различных алфавитных системах попали почти все буквы современной кириллицы, кроме Ж, Н, Р, Ц, Ч, Я. Рассмотрим и эти буквы.
Буква Ж стоит перед 3, имеющей числовое значение 7 и потому может быть сближена с буквами шестой колонки, конкретно с X. По-видимому, она и представляет модификацию последней, лигатуру X с Алифом (единицей), что иногда используется для изменения порядка числового значения.
Если буква х (в рукописном варианте) оказывается сложенной из двух шестёрок (запятых), перевернутых по отношению друг к другу, то эти же шестерки сохраняются и в букве Ж. Здесь нелишне вспомнить, что символ шестого региона (инь-ян) как раз и состоит из этих двух шестерок-запятых. В протоалфавите стояла губная Вав (шестерка). А у нас почему-то Ж. Действительно, почему?
Смотрите как важно правильно задать вопрос. Вот и ответ. Главной категорией китайской философии является понятие жень "человек", поэтому и женский вопрос получил в Китае такое особое внимание. Поэтому и в кириллице, в алфавите тех, кто создал азбуки для других народов, в том числе и для Китая, исконный Вав замещен сконструированной буквой Ж.
Современное начертание буквы Н производно от более древней кириллической N и появилось, по всей видимости, для устранения путаницы между И и N. Что такая путаница может иметь место, я убедился, обучая арабов русскому языку.
Кириллическое Р стоит после П, имеющего числовое значение 80, так что Р – это развернутая в другую сторону девятка. То, что числовое значение этой буквы не 90, а 100, объясняется тем, что в русской азбуке исконные девятки изъяты со своих мест и помещены в последнюю строку цифровой матрицы.
Буква Ц имеет числовое значение 900, по звуковой характеристике соответствует еврейской букве Цаде (90), в которой слились две арабские эмфатические: Сад (90) и Дад (800). Но если мы перевернем нашу букву Ц, получим начертание, похожее на П (80) или на еврейский Хет (8). Возможно, числовое значение и место буква Ц занимает по звуковому соответствию, то есть как бы из девятой колонки, а по начертанию она похожа на восьмерку в форме буквы П.
Буква Ч имеет числовое значение 90 и, как и Ц, соответствует арабскому эмфатическому С#ад. Поэтому можно предположить, что Ц и Ч модификации одного и того же начертания, тем более что их сходство очевидно.
Последнюю букву нашего алфавита Я, имеющую числовое значение 900, перевернем и получим почти точную копию арабского эмфатического З#а ( ظ = 900). Впрочем, в нашей Я и без арабского видна девятка. Эта буква была введена довольно поздно и потому совпала с соответствующей арабской по причине выражения одного и того же числового значения.
Особый разговор о некоторых начертаниях русской буквы Д. Заглавная наша буква вместе с греческой Дельтой заглавной ( D ) может быть возведена к арабской четверке. Здесь нет вопросов, коль скоро числовое значение этой буквы – 4. А вот наша курсивная д , вместе с латинской d и греческой d так просто к четверке не сводится. Более всего они похожи на девятку или шестерку. Коль скоро так: они должны быть сближены с арабской Д# эмфатической, которая имеет числовое значение 800, а обозначается вместе с другими эмфатическими девяткой: ضـ .
Как видите, вся русская азбука сводится без остатка к арабской цифровой системе письма.
Бытовавшие в древности в нашей азбуке буквы греческого алфавита были заимствованы по причине сильного влияния христианства. Однако греческие буквы не отражают звуковых особенностей русской речи и потому со временем были изъяты как чуждые элементы без всякого ущерба для русского языка. Действительно, зачем русскому языку две буквы Т: Твердо и Тэта (Фита), если у нас всего лишь один звук Т, а для Ф есть своя буква. Очевидно, в русской азбуке Тэта (Фита) появилась для передачи греческой орфографии при переводе Евангелия. О том, что эта буква пришлая, говорит и то, что она одинаково обозначалась в двух разных русских азбуках, кириллице и глаголице, в которых почти все буквы различаются.
Итак, известные нам письменные системы являют собой не разные системы, а одну, модифицированную применительно к каждому региону. То же следует сказать и о языке в целом. Мы все говорим по сути на одном языке, если точнее, на языках, представляющих собой разные модификации одного.
Пролазы
Образование и функционирование этих языковых модификаций сопровождается разного рода явлениями, которые я называю пролазами.
Электронщики противовоздушной обороны называют пролазами или пролезаниями попадания в канал связи постороннего сигнала. Например, в целевой канал ракеты может попасть отражение от местных предметов. Ракета, вместо чтобы идти на цель, может захватить этот посторонний сигнал, так называемый местник, и изменить направление.
Результаты бывают плачевные.
Пролазы по созвучию (омонимии). Точно такие же пролазы наблюдаются при работе головного мозга. Головной мозг, как и ракета, имеет канал цели. Если головной мозг не различает похожие сигналы, например созвучные слова или омонимы, человек вместо своих функциональных обязанностей, совершает странные поступки.
Римский сенат в самом начале насчитывал ровно сто сенаторов. Почему? Потому что название этого органа созвучно латинскому цент "сотня". Наверно, римские сенаторы посчитали это созвучие указанием от Бога. Есть такая привычка у людей. Собственные глупости списывать на Бога. Другие скажут, ах вот откуда название законодательного органа. Это логика замороченной филологии. Сенат от арабского سنة СНТ "закон", а цент – от русского сто. Ничто кроме случайного созвучия эти слова не связывает. В США и сейчас сенаторов
ровно сто человек. Вообще-то безобидная заморочка. Бывает похуже.
Дума по-арабски ( دمى ) означает "куклы". Наш парламент по-арабски так и называется "совет кукол". Неразличение омонимии не проходит бесследно ни для одного парламента.
Почти по всему миру в той или иной степени происходит подмена функциональных обязанностей разыгрыванием кукольных спектаклей.
Пролазы в головном мозге не обязательно приводят к его разрушению, поэтому могут действовать всю жизнь. В других случаях созвучия могут привести к самоуничтожению. В древности, на праздник масленицу русские воины обливались маслом и входили в костер. Трагедия происходила от неразличения слова масленица как праздник солнца (сложение показателя времени и места ма со словом СЛНЦ т.е. солнце) и слова масленица "то, что связано с маслом". Понятие масло постороннее понятие для русского обрядового праздника встречи солнца. Но русские подвязывают его по созвучию к маслу и пекут блины, выход на солнце уже более безопасным способом
Пролазы бывают не только по созвучию.
Графические пролазы. Когда еврей читает букву Р, а она пишется как русское Г, то этот кириллический пролаз моментально накладывается на произносительную моторику, в результате чего появляется характерная картавость. На это обстоятельство обратил мое внимание В.А. Пономарев.
В русской детской речи иногда наблюдается замена Л на И. Такие дети говорят: ямпочки, буявочки, гайоши. Причина состоит в том, что некоторые славяне используют не свою письменность, из-за чего происходят латинские графические наводки на русскую речь, ведь латинские I и L в определенных случаях пишутся одинаково: golden.
По той же причине даже в речи некоторых взрослых наблюдается замена Л на В. Особенно это характерно для поляков, говорящих по-русски. Говорят свово вместо слово. Сравни: L и V.
Подобные графические пролазы носят тотальный характер. Если они наблюдается у человека, то наблюдается во всех случаях прочтения им данных букв.
Графические пролазы бывают также единичными. Они связаны не с личностью, а с конкретным словом. Так, арабский Ъайн ( ع ) читается как греческое, русское, латинское Е. Это происходит в словах ЕЛЕМЕНТ "знак алфавита" (لامة + ع – "знак" ), СЕРА ( ر ع س – "воспламеняться"). В других случаях Ъайн пролезает как О. (Орфей, морфа, форма, лето). Условно я их называю финикийскими пролазами поскольку именно в финикийском алфавите Ъайн обозначался кружком.
Рассмотренные случаи говорят о том, что графические образы данных слов представлены в подсознании в арабской графике, но в раздельном написании (буквы отделены друг от друга пробелами) Слитное написание предполагает чтение вместо Ъайна У утлый и утиль от عطل ут#т#ил "быть приведенным в негодность"). Впрочем, этот пролаз можно было бы назвать арамейским, поскольку в древнеарамейском (и еврейском) алфавите Ъайн обозначается как У (начертание взято от Ъайна в начале слова: عـا ).
Вот еще несколько примеров на графические пролазы.
Инцест в имени матери и жены Эдипа пролез как Иокаста. Об этом мифе речь пойдет позже. Причина пролаза в том, что буквой О обозначают в арабском пятую букву, которая в середине слова пишется как греческая N .
Графический пролаз и в имени римской богини ремесел Минерва, в котором Н следует читать по-латыни, тогда получим арабское слово مهارة маха:ра "мастерство".
Русское числительное шесть от обратного чтения тисъ в раздельном написании ع س ت "девять", где Ш результат бокового чтения Ъайна ( ع ).
В арабском языке буквы Д и Р плохо различаются, если рассматривать их вне буквенного и смыслового контекста. Отсюда арабское روح ру:х# "дух" читается как дух, арабское رش рушш "брызгай" читается как душш "душ".
Звуковые пролазы. Колебания между Г, Й, Ж, например, в вариантах имени Жора, Юра, Георгий отражает диалектные варианты произношения третьей арабской буквы Гим. Это результат звуковых наводок, идущих от арабских диалектов.
Структурные пролазы. При написании арабскими буквами русского выражения лакомый кусочек обнаруживается, что лакомый от арабского لقمة лук#ма "кусочек", а кусочек от арабского كويس кувеййис – "вкусный", "лакомый". Дело здесь в том, что арабская грамматика требует постановки определения после определяемого слова, тогда как в других языках, в частности в русском, дело обстоит противоположным образом. Пролаз состоит в том, что на материале русских звуков остается структура оригинала. То же в астрономия, где первый компонент не "звезда", а "описание" ( СТР اسطورة ), второй – "звезды" ( نجوم нйум > ном), а не "закон". В латинском ursus arctos "бурый медведь" на самом деле первый компонент не "медведь", а "бурый", ср. латинское rusus "красный", а второй – не "бурый", а "медведь", сравни греческое arkto "медведь".
Вот еще своеобразный структурный пролаз. Цифра 9 в перевернутом виде обозначает число 6. Отсюда в арабском ست стт "шесть", تسع тисъ "девять". Вслед за цифирью переворачивается и корень.
Еще один такого свойства, о котором мы вели речь по другому поводу. В цифровой матрице порядки чисел различаются ракурсом соответствующей цифры. Число 2 обозначается цифрой 2, число 20 обозначается цифрой 2 в перевернутом виде, число 200 – цифрой 2 при дальнейшем ее вращении. Так же и в русских словах ср. десять – сто – тысяча, где вращается корень ТС-СТ-ТС (при озвонченном первом согласном в слове десять).
Среди пролазов встречаются уникальные. Русское слово сутки не имеет логичной этимологии. Между тем, первая часть сут от арабского военного сокращения سعت саъат "часы". Она складывается с согласной Кяф (كـ), имеющей числовое значение – 20 и далее с согласной Даль ( ـد ), числовое значение которой – 4. Даль, однако, зачастую пишется очень похоже на русское И рукописное:

отчего и получается слово сутки, значение которого буквально: 24 часа. В слове два пролаза. Один – обычный, когда Ъайн читается как У, второй – уникальный, делающий арабский Д русским И.
Вот уникальный пролаз в семантике. В некоторых славянских языках мышьяк называется арсеник. Это название идет из латыни, а там – из греческого: arsoenikoV "мужской". Почему же потрава для мышей называется таким странным словом? Где здесь логика? Что касается слова мышьяк, то я считаю его исконно русским. Поскольку именно в русском мотивированность его предельно прозрачна: оно складывается из слова мышь и арабского يقي йак#и: "защищать". Следовательно, мышьяк это средство, защита от мышей. Имеется аналогия такому словообразованию. И в русском, и в арабском языке есть слово тиръяк "противоядие". Тир – это то, что осталось от слова отрава, а як – тот же, что в мышьяк. Здесь все на месте и логика, и аналогия. А вот с арсеником не понятно. Видимо, какая-то калька. Надо искать язык, в котором бы название вещества было созвучно со словом, выражающим значение "мужскости". Таким языком оказывается русский. Мужик по составу согласных мало отличается от слова мышьяк (МШК = МЖК), причем различающиеся Ж и Ш относятся к классу гоморганных. Таким образом, и в греческом, и в латыни и в некоторых славянских языках название мышьяка – ложная калька с русского.
Пролазы бывают оказиональные, связанные с конкретной ситуацией. Мне однажды пришлось слушать лекцию Кандаурова об арканах Таро. Лектор, рассказывая о седьмом аркане, вдруг, на первый взгляд, немотивированно, переходил к третьему. Я обратил внимание, что понятия, которые почему-то связывались в голове у лектора, в переводе на арабский имели сходство по звучанию. К сожалению, я не записал тогда эти моменты. Но вот случай, зафиксированный мною.
Рассчитывали, что груз придет как раз к Новому Году, и в контейнер положили сибирские елки. Груз пришел намного позже. Пришлось елки эти выбросить. Так в Африке оказались ели. Один из аборигенов, увидев, что елки еще зеленые, решил их посадить. Сажает и приговаривает. На своем языке, разумеется. Вот это Ельцин. А вот это его сын. Бред какой-то. Откуда такие ассоциации? Если созвучие ель и Ельцин, так абориген знает только одно русское слово – Ельцин. Более того, откуда он знает, что при сравнении ель и Ельцин, в остаток выпадает цин, созвучное с русским сын? Это выглядит каламбуром, если знаешь русский. Но на русском не принято так шутить. Когда меня наши спросили, что он говорит, я не решился перевести правильно, подумают, чокнулся мужик. Этот бред понимается нормально только на фоне привычки египтян обыгрывать любые слова.
Пролазы бывают причиной распространения ложных калек. В арабском свадьба по какой-то причине называется словом со значением "радость" – فرح фарах#. Понятно, что свадьба – радость для жениха и невесты и их родственников. Но разве мало других радостных мероприятий? Радость не связана исключительно с церемонией бракосочетания. Кстати сказать, русский корень СВД, извлеченный из слова свадьба, совпадает с арабским سعـد СЪД "счастье", при том, что арабский Ъайн иногда соответствует в других языках букве В (w), сравни русское бечева и арабское (в обратном прочтении) عـصب ъас#аба "вязать". Вот другой пример, на этот раз из научной терминологии. Из генетики известно, что в любой клетке каждая хромосома (буквально: "цветное тело") представлена дважды. Одна получена от отца, другая – от матери. В обычном состоянии хромосомы не наблюдаются в клетке, однако перед ее делением происходит их спиралезация. Они собираются в пару спиралей и закручиваются вокруг друг друга. Акт воспроизводства клетки весьма похож на обычный акт брачевания, который имеет место в человеческом обществе. Но почему эти тела называются цветными? Оказывается, немецкий ученый В. Вальдеййер описал хромосомы в 1888 году как интенсивно окрашивающиеся плотные тельца (10, т. 28, с. 397). Впоследствии выяснилось, что окраска к тельцам не имеет отношения. Ученый выбрал неправильный или несущественный признак. Термин, однако, живет и никто не думает его менять. В чем дело? А дело в том, что Вальдеййер назвал эти тельца правильно. Но чтобы это понять, надо читать термин по-арабски, в обратную сторону. Сома в обратном прочтении дает корень مس МС "касаться", "щупать". Собственно, греческое сома "тело", потому так и называется, что оно доступно тактильным ощущениям. Другая часть в обратном прочтении дает арабское مرح марах "веселье", "радость", то есть свадьба, брачевание. Так почему же все-таки свадьба называется радостью? На мой взгляд все дело в пролазе, в созвучии между русским радость и названием женской функции воспроизводства по-русски родить, по-арабски رضع рад#аъа "вскормить (грудью)". Отсюда в арабском أرض 'ард# "земля" (мать-кормилица), русское родина, почти буква в букву совпадающее с арабским أراضينا эара:д#и:на: "наши земли". «Образ матери-кормилицы – образ не метафорический. Наше слово земля идет от арабского حمل = زمل замала = х#амала "нести", "беременеть".
Опять вернемся к хромосоме и увидим, что функция воспроизводства записана и в прямом прочтении: حرمة х#урма "жена", в обратном прочтении مرح МРХ# – опять "радость". Неплохой и даже, наверное, полезный пролаз, если это пролаз. Во всяком случае, по статистике женатые мужчины показатели смертности имеют в четыре раза меньшие, чем холостые.
Этногенез
Сам арабский язык, хотя и подвержен изменениям тоже, все же как бы застыл, в особенности, если его рассматривать в отвлечении от диалектов. Но и сам арабский содержит заимствования. Например, почти вся культовая терминология из русскою языка, включая такие термины как хадж, в арабском произношении حج х#ажжун, от русского хожение; اسلام ислам "покорность", от русского сломать, т.е. покорить; суфизм, по-арабски تصوف тас#аввуф, аскетическое течение в исламе, пишется в четыре буквы ТСУФ, которые в обратном прочтении дают русское пустынь "обитель монаха-отшельника". Есть русизмы в арабском и в области государственного управления и финансов. При внимательном обследовании культов других регионов выясняется, что и там базовые термины религиозных культов – русского происхождения. Все это говорит о том, что некогда в протоимперии, как уже было сказано выше, власть перешла к первому региону, о чем, собственно, и повествует древнеегипетская фреска о сотворении мира.
Неопалимая купина
Можно предположить, что некоторое время протоцивилизация управлялась из двух центров. Один – административно-финансовый, другой – духовный. С этой точки зрения показательны названия культового центра арабов – Каабы и столицы древней Руси – Киева. Собственно Киев и Кааба (мн. число: كعاب Киаъ:б) – это одно и то же слово, несколько по-разному прочитанное.
Появление Киева знаменует собой удвоение куба. До нас это событие дошло в форме притчи о математической задаче удвоения куба. Если ее не решить, все погибают. С точки зрения математики это не такая уж сложная задача. Трудность ее смехотворна, она состоит в том, что возникает необходимость оперировать бесконечными дробями. Любая инженерная задача такова. Если над этой проблемой размышляли математики Вавилона, стоит ли удивляться, что их башня рухнула недостроенной. Эта задача решается, как и любая инженерная задача, примитивными правилами округления. А вот политическая задача удвоения Куба, в смысле создания второго центра, и в самом деле была судьбоносной. Но и она была успешно решена.
Союз двух четверок запечатлен многократно в виде самых разных следов. Возьмите названия дней недели. У нас есть четверг и есть еще среда, т.е. середина. То же в этимологической нумерации знаков Зодиака.
В древнерусской иконе "Неопалимая купина" изображение богоматери помещено вовнутрь двух квадратов-близнецов. Один – красного цвета, другой – зеленого. Подвигнуло богомаза на изображение квадратов созвучие древнего слова купина с арабским كعوب куъу:бун "кубы". Тоже след задачи удвоения куба. Причем, نفل НФЛ (неопалимая), по-арабски "добавление"
Человеку, однажды пережившему распад империи, нетрудно представить ситуацию в протоцивилизации накануне перехода власти к Руси. Регионы стремились к самостоятельности, требовали узаконить те языки, которые в них сложились естественным образом за счет постепенных изменений вопреки стараниям центра. Они хотели бы иметь эти новые языки в качестве государственных. Ситуацию на местах лучше всех знали русичи, поскольку их гарнизоны находились во всех регионах. Русичи знали также, что, получи регионы самостоятельность немедленно, их бесписьменные языки не позволили бы сохранить культуру. Население регионов моментально выродилось бы в дикие племена. В ставке велась картотека на вероятных противников, а ими были в основном полудикие племена, некогда бежавшие за пределы цивилизации. Было видно, что степень культуры того или иного народа напрямую зависела от возможности письменной фиксации знаний, т.е. от наличия письменности. Понятно, что новые языки не имели пока своей письменности, так что в случае развала Империи их носителям грозило культурное вырождение.
Чтобы этого не произошло, первый регион берет власть и разрабатывает для бесписьменных народов письменности. Собственно, этот процесс повторился, когда в двадцатые годы в Москве были разработаны алфавиты для народов, никогда ранее не имевших письменность. И до сих пор в разных системах письма, включая и китайскую грамоту, внимательный глаз заметит следы кириллицы (подробнее см. "Утраченная мудрость"). Русь юридически закрепляет изменения, произошедшие в регионах, тем самым опять же юридически фиксирует начавшийся процесс этногенеза. Впрочем, Русь и сейчас занимается тем же. Это понятно. Как регион, отвечающий за сохранность цивилизации, Русь должна порождать все новые этносы, поскольку множественность путей развития – один из факторов надежности.
Интересно, как по-разному арабы и русские относятся к своему языку и, вообще, к действительности. Фраза сразу жизнь становится иной, будучи переведена на арабский язык буквально, означает совсем противоположное: "жизнь стала совсем плохой": حال حالي х#а:ли: х#а:л. Любые изменения, а в особенности в языке, осознаются арабами как порча, даже грех. Их задача – сохранить в неприкосновенности язык, не дать ему измениться. И это правильно, поскольку арабский язык – это не язык арабов, а язык всего человечества. Как и русский.
Схема этногенеза следует схеме глоттогенеза. Русь, сама встав на путь изменения языка, показала другим этносам, как это делается и закрепляется юридически.
Нетрудно видеть, что схема развертывания этносов, как и схема химических элементов – это не более как формула Пресвятой Троицы, одна из разновидностей угла (единицы). Именно этот угол мы наблюдали и в структуре цифр и букв, и в структуре звуков, и в структуре карточной игры и в структуре уровней бытия и даже в структуре периодической системы элементов.
Ну, а что касается двух центров, так это тоже универсальный закон бытия. Ср. например, Водород и Гелий в плазменном веществе, Луну и Солнце, светила, определяющие приливно-отливные и биологические ритмы нашей планеты, или взять рациональное и эмоциональное в нашей психике. Даже если мы вернемся к наиболее простой форме Пресвятой Троицы, к обыкновенному углу (единице), мы и там найдем два центра. Этими центрами будут два конца линий, совмещенных в одной точке. В одних структурах эти две точки слиты, в других раздваиваются, ибо это раздвоение есть естественное движение, начало эволюции.
В таких сложных многоярусных, многоэлементных и многомерных структурах как язык, не сразу разглядишь Пресвятую Троицу, но то, что идя по ее следу мы раскрываем не только все тайны, так или иначе связанные со словом, но и тайны бытия, тайны рождения и смерти, тайны законов поведения и т.п. важный признак того, что мы идем по правильному пути.
Роль арабского в системе этнических
языков мира может быть лучше понята на фоне такого явления как голография.
Известно, что волна любой природы имеет три главных параметра: амплитуду,
частоту, и фазу. Если мы умеем отображать только амплитуду, на фотографии будет
черно-белый плоскостной рисунок. Если мы научились отображать и частоту волны,
получим цветную фотографию. В последнее время люди научились благодаря лазеру
отображать и фазу. Для этого объект снимается при лазерном освещении. Но чтобы
получить объемное изображение, мы должны облучить фотографию тем же опорным
лазерным лучом, который использовался при съемке. Если это сделано, получается
то, что называется голографией. Арабский язык как раз и является подобным
опорным лучом, при освещении которым слова самых разных языков становятся
объемными, понятными и начинают отдавать ту информацию, включая и историческую,
которая в них заложена.
Вначале было слово
Итак, мы рассмотрели семь уровней развертывания человеческого языка от точки до этнического языкового многообразия. Зная этот механизм, можно констатировать, что имеется принципиальная возможность свести (почти) любое слово любого языка к точке, тем самым показав историю возникновения любого слова и, следовательно, любого языка.
И другое. Принято считать, что любой язык – продукт определенного этноса. В известном смысле как раз наоборот. Этнос – продукт соответствующего языка. Ведь вначале было слово.
Принято считать, сознаюсь, и я, к стыду своему, всю жизнь так думал, что язык есть средство общения. Это его главная функция, а все остальные функции (специалисты насчитывают до десяти и более) в конечном счете могут быть сведены к коммуникативной, то есть к функции общения.
Если вдуматься, общение как таковое вовсе не нуждается в таком сложном механизме, каким является человеческий язык Достаточно примитивного языка типа языка пчел или муравьев, благодаря которому они успешно существуют и организуют свои общества. В подтверждении этой мысли сошлюсь на известный и описанный в литературе опыт одного англичанина, который, выбрав себе для общения несколько десятков слов, успешно обходился ими в течение нескольких лет. Можно сослаться и на литературные примеры, хотя бы из Ильфа и Петрова. Принципиальная возможность общения на примитивном языке и даже возможность общения молчанием подсказывает нам, что дело здесь в другом Общение в том виде, как оно существует среди людей, нужно не столько самим людям, сколько, образно говоря, Господу. Речевая активность людей снабжает смысловое поле морфологией и лексикой, кирпичами, из которых складывается морфология космического Интернета, кибернетического устройства, управляющего миром, в том числе и людьми. Это кибернетическое устройство и есть Язык, Слово, которое вначале, и которое у Бога и которое Бог.
Русский и арабский языки составляют в этом Слове плазму. Точно так же, как водород и гелий составляют плазму физическую, русский и арабский составляют плазму духовную.
Другие этнические языки образовались в результате модификаций языковой плазмы. Они, однако, являются не результатом их прошлых состояний, как принято считать в языкознании. Этнические языки суть отражения языковой плазмы при выводе ее вовне.